Model Validation in openLCA
In a life cycle assessment (LCA), it is not enough to simply construct a model and calculate results. According to the ISO 14040/14044 standards, the study must also be validated to ensure that it reflects the intended goal and scope. Validation is about confirming that the model is complete, consistent, and reliable. openLCA provides several features to help practitioners perform this step systematically.
openLCA supports LCA practitioners in conforming to the ISO14040/14044 by:
| ISO 14040/14044 Requirement | openLCA functions/features supporting it |
|---|---|
| Validation of data | - "Model Graph" (to visualize product system) - Disconnection of processes from the product system to review LCI for mass and energy balance |
| Identification of significant issues | - "Contribution Tree" to identify dominant processes/flows - "Sankey Diagram to visualize impacts - "Contribution Tree" for hotspot detection |
| Consistency check | - Consistent use of physical units (flow properties) - Same allocation rules and numerical cut-off throughout the product system - "Parameter Sets" for scenario consistency - Data Quality Assessment of results |
| Completeness check | - Database Validation (detects errors and missing links) - “Check linking properties” function (unlinked flows) - Detection of unmapped flows ("LCIA Checks") |
| Sensitivity check and Uncertainty analysis | - Parameter variation via "Parameter Sets" - Scenario comparison in "Projects" - Hierarchical parameter logic - "Monte Carlo Simulation" for uncertainty propagation - Visualization of data quality in results |
Validation of data
Already during the data collection, data validation and mass/energy balance must be ensured in LCA studies. However, LCA models can be complex and after building the product system, practitioners should analyze if those balances are still given. To conduct this but also to get an overview, openLCA lets you probe the structure of the product system directly. For example, you can disconnect selected processes, see Model Graph, to test for inconsistencies in mass or energy balances, or to explore the role of specific flows such as energy use or transport demand to cross-check with your data entries:
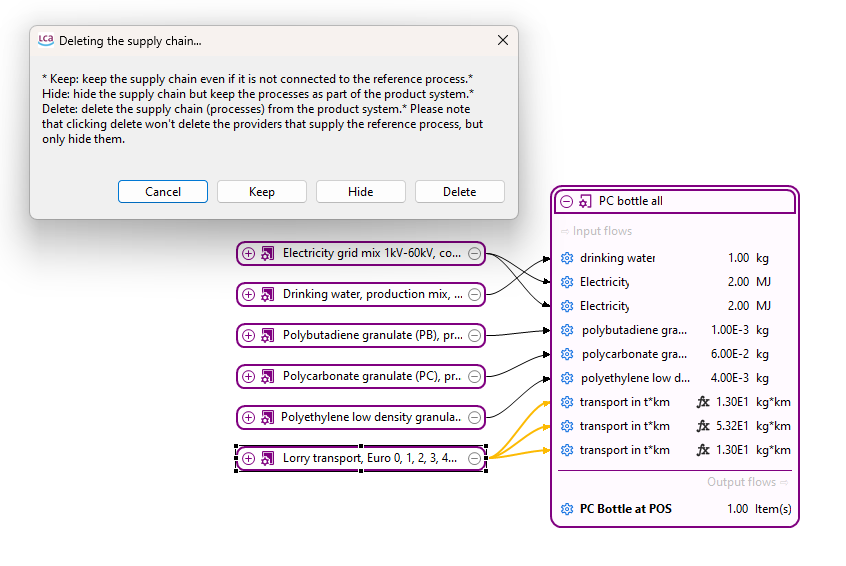
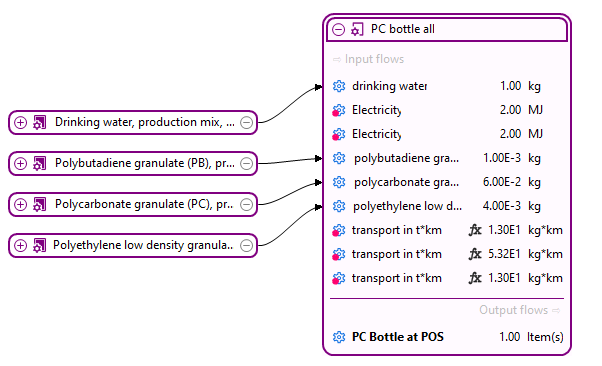
The respective inventory will display the amount of needed energy or transport over the whole supply chain, as the processes have been removed from the supply chain. This helps you understand how much each process contributes to the overall resource demand and highlights potential data gaps or imbalances that may require correction or further justification.
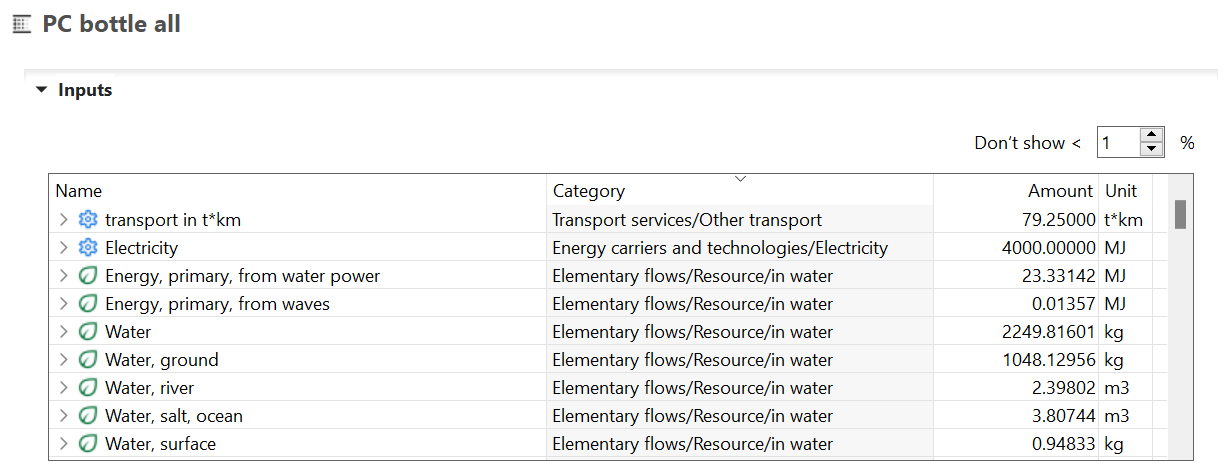
This logic allows you to further investigate the disaggregated life cycle inventory in detail, but also to review mass and energy balances if you consider the whole life cycle of a product. However, by partly disconnecting relevant product flows, it allows you to prove that the sum of product flows equals the sum of the waste flow:
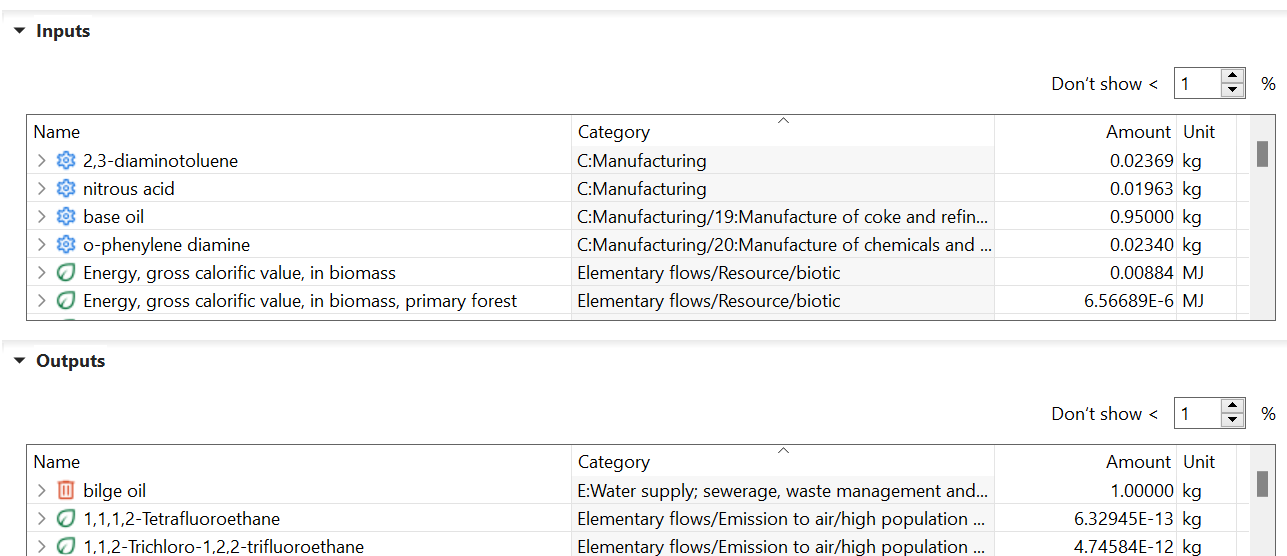
Hence, you could consider that the masses in your investigated part are balanced. Combining the approach with assessing the Data Quality of your product system allows you to investigate the foreground and background data quality of the product flows.
Identification of significant issues
The goal here is to identify key issues by organizing the LCI and LCIA results in a way that emphasizes the most relevant aspects of the study. Significant issues may include disproportionate contributions of certain flows (e.g., energy, emissions, waste), impact categories (such as climate change, resource use, etc.) or particular life-cycle stages and processes (e.g., transport, energy supply, production steps). To conduct this step, openLCA supports the user through the Contribution Tree and Sankey Diagram, which visualize dominant processes and flows. Users can interactively navigate through subprocesses to identify environmental hotspots of their product system, which is not only helpful for the interpretation of the results but also to comply with the identification of significant issues.
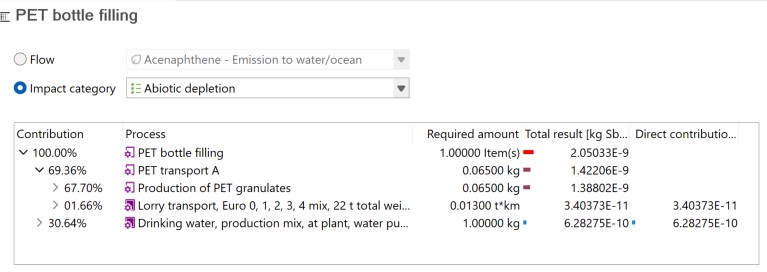
Consistency check
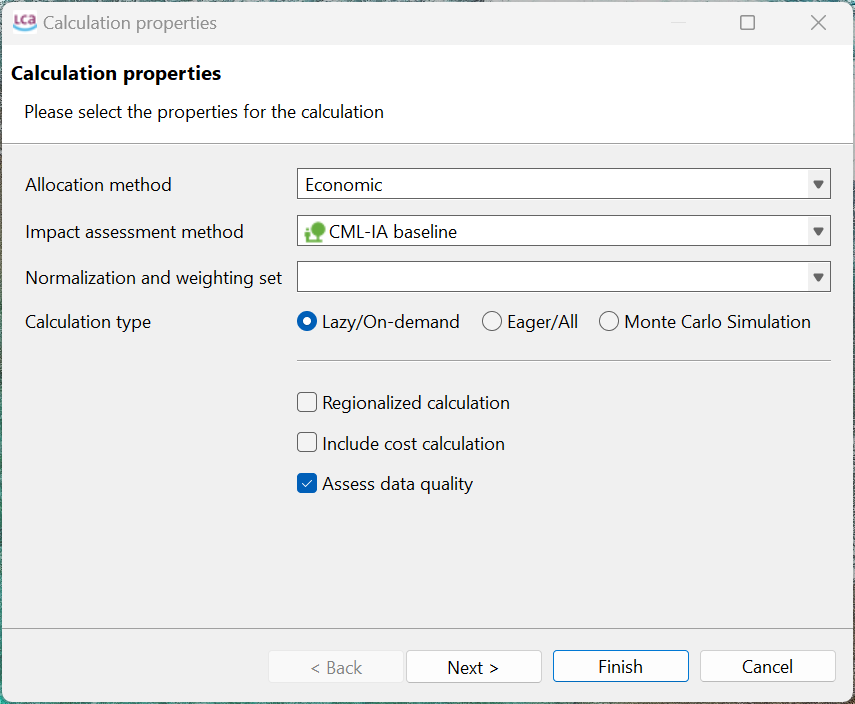
The consistency check ensures that the assumptions, methods and data are applied coherently throughout the study. This involves verifying that differences in data quality are justified by the goal and scope, that regional and temporal aspects are handled in a uniform way and that system boundaries and allocation rules are applied consistently across all modeled systems. The same principle applies to the use of impact assessment methods, which should be applied consistently across the study. openLCA inherently supports this criterion, so users do not need to worry about enforcing it themselves. openLCA supports the usage of the same physical units, conversion factors, allocation principles and impact assessment methods throughout the product system. This includes ensuring that allocation settings (e.g. economic throughout all processes in calculation setup) or numeric cut-off rules (see product system setup) are defined uniformly within the product system:
Furthermore, openLCA supports the user by handling units and flow properties consistently throughout the database, see Background data. Databases that are obtained from openLCA Nexus and new databases ('from scratch') already hold harmonized units and flow properties. This avoids errors caused by mismatched units or flow definitions and ensures that all data can be compared and aggregated reliably, for example, by automatically converting grams to kilograms or kWh to MJ when needed.
Further, functions such as the Parameter Sets allow users to systematically review and confirm that assumptions are applied consistently across all model variants. This means that when exploring alternative scenarios (e.g., different energy mixes, technologies, or allocation rules), openLCA helps ensure that changes are applied in a controlled and transparent way, making comparisons between scenarios more robust.
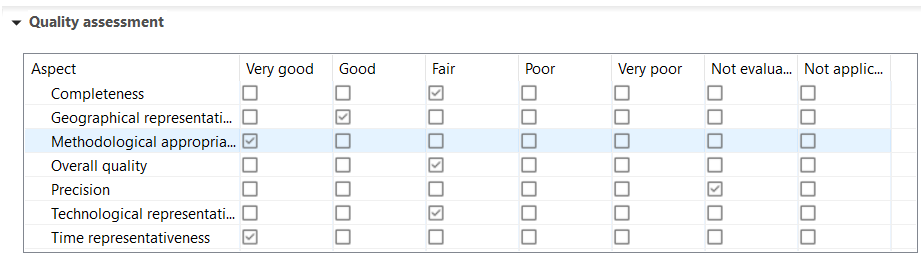
However, to ensure that the required regional and temporal aspects are represented in the Data Quality in a uniform way, the data quality of your inventory and impact results can be assessed during the calculation phase. The results indicate whether the flows and processes that contribute most to the results are supported by high-quality data in the regional and temporal context, helping practitioners identify hotspots where data may need to be improved or replaced.
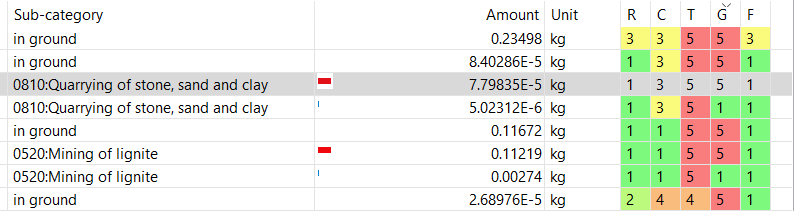
Large differences of data quality in processes or flows, in particular in the foreground model, should be justified in the LCA study.
Some databases, here Carbon Minds, also provide an overview of the reviewer's quality assessment of datasets in the Documentation tab. This can further indicate potential issues.
Sensitivity checks and uncertainty analysis
The sensitivity check examines how robust the results are when faced with uncertainties in data, modeling choices, or calculation procedures. This means testing whether the conclusions change significantly if input data varies, if allocation methods are adjusted, or if certain assumptions are altered. openLCA supports this by allowing you to perform sensitivity and uncertainty analyses and observe how the results respond.
openLCA ensures sensitivity checks by offering integrated options for parameter and scenario variation. You can use parameters in your foreground model and adjust these at several stages of the openLCA database Hierarchy. In the product system, you can then adjust them systematically via parameter sets and rerun the calculations to observe changes in results. Projects in openLCA make it easy to compare different scenarios side by side, allowing the re-definition of parameters between scenarios of the same product system. A relevant example could be to prove your assumption that the catalyst within the PET granulate product could be omitted in your LCA study, as they fall under your cut-off criteria (<1% of mass inputs). To later demonstrate this assumption, you perform a sensitivity analysis using openLCA’s project function.
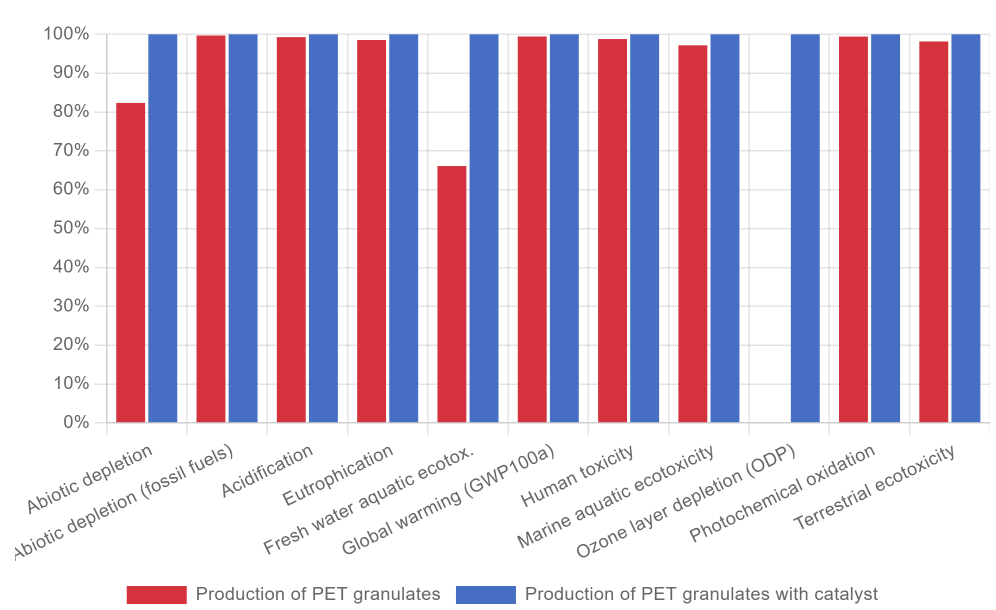
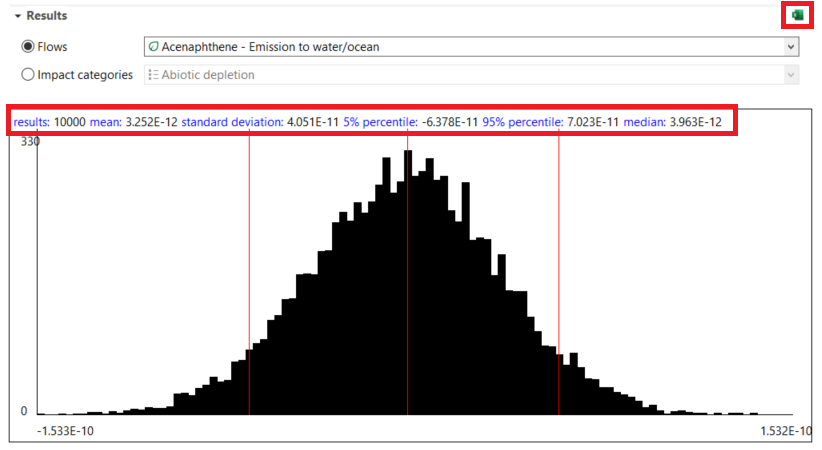
As visualized, in most impact categories, the change of impacts was rather marginal. Hence, this backs the previously made assumption. However, if this would be more drastic, the outcomes of the sensitivity analysis would imply to redesign the LCA studies’ assumptions. Uncertainty analysis in openLCA is done by allowing uncertainty information to be stored with input and output data that can be applied during calculations. Then, Monte Carlo Simulation simulations can be performed directly in the software to generate a distribution of results rather than a single point value. The outcomes can then be visualized, making it possible to evaluate how stable the study’s conclusions are when accounting for uncertainties.
Completeness check
A completeness check verifies that all the necessary data and information are available for the calculation of results. If important processes or flows are missing, you need to evaluate whether they are critical to fulfilling the goal and scope of the study. This can be performed in certain ways in openLCA.
First, after you have finished modelling, you should check that the validation of your database does not return any errors and that all providers are set across your entire database. openLCA supports this process through database validation and the 'Check linking properties' function, see Toolbar. The latter scans the database for unlinked product flows and waste flows. Running this check helps ensure that all exchanges are properly connected. Databases provided on openLCA Nexus are offered with a clean validation check and, in cases of high-quality databases, also the “Linking Properties” of the database look like this:

If you run into linking errors, analyze the reasons. If it is due to data you changed in the background data, you can export your foreground model and re-import it into a new database. Some background databases hold flows with several providers, which is not a problem, just should be taken care of that in the processes, are respective 'default provider' is set to prevent ambiguity.
Another layer of completeness is required to be tested on the LCI and LCIA levels. Initially, you have to make sure that your life cycle inventory does not hold any product flows anymore, as they will not be characterized by the LCIA method.
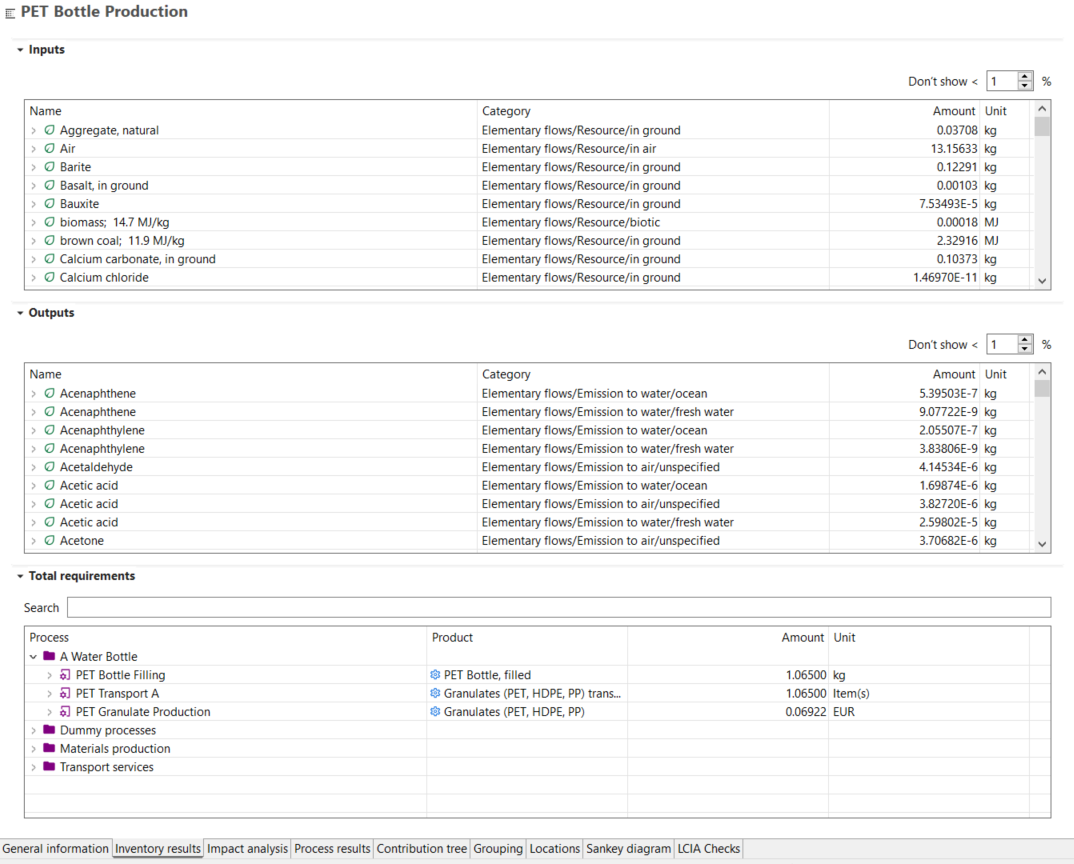
Once done, you have to make sure that during the impact assessment, undefined or unmapped elementary flows are minimized as they can compromise the completeness and reliability of the results. Here, openLCA supports you with the LCIA Checks tab of the Result window in post-calculation by displaying all the flows that are not assessed in the respective impact category.
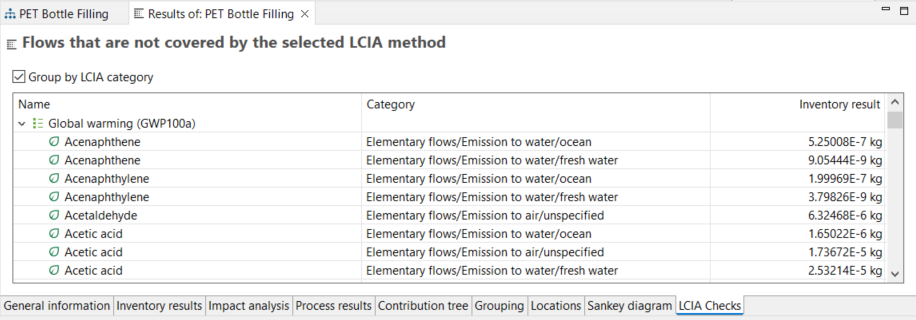
If you find here elementary flows that should be assessed, you have to provide them a characterization factor in the method or exchange them in the respective process. This can occur due to mis-mapping of flows, e.g. carbon dioxide (fossil) vs. carbon dioxide, fossil. Only one of them is commonly assessed.