Databases
In openLCA, a "database" functions as a container that organizes and stores interconnected elements needed by openLCA. It serves as a repository for projects, product systems, processes, flows, results, and other important components required for conducting LCAs. Key elements of an openLCA database are shown below, with their relations.
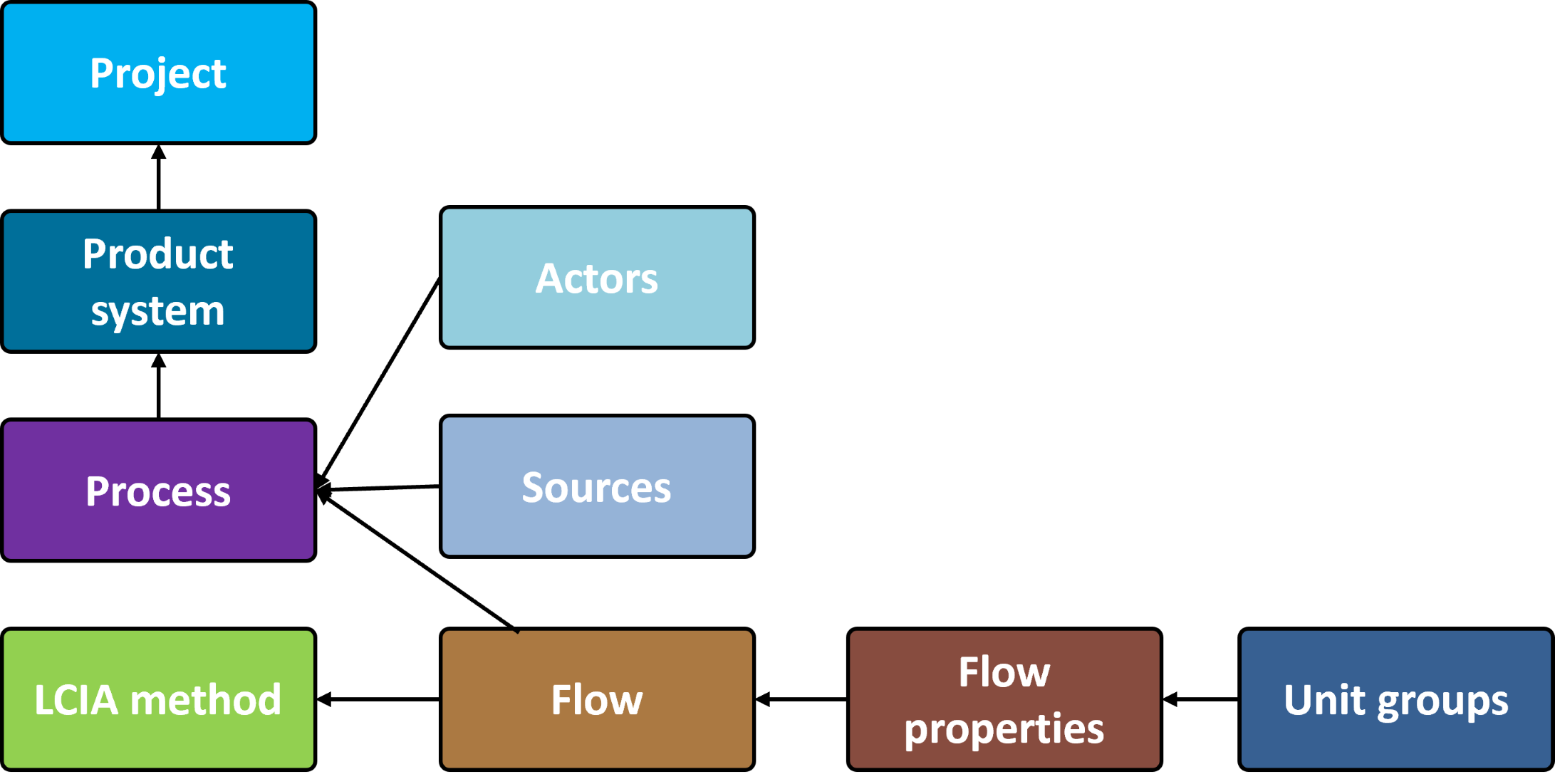
Database elements. The direction of the arrow represents the direction in which the information flows.
After launching openLCA for the first time, you will notice that the navigation section is empty. To start working with openLCA, you can either create a database from scratch or load one from an existing file (e.g. one you might have downloaded from openLCA Nexus, in this case follow the instructions for "Accessing databases from openLCA Nexus" on openLCA Nexus section). You can also load a database from a GitHub repository("New database" > "From repository...").
![]()
Empty Navigation window following openLCA installation
openLCA offers the flexibility to have multiple databases imported in the software. Each database functions independently and only one database can be "active" at a time, while the others remain "inactive". This allows you to separate different LCA studies or case studies for better organization and management.
However, with openLCA it is also possible to combine multiple databases, by merging their content. This feature enables comprehensive analysis that incorporates various datasets and LCA models. Check "importing and combining databases" section for details.
Note: It is considered good practice to work with one database for each case study/LCA project performed in openLCA.
New! Now in openLCA 2 you are able to sort your databases in folders. Right-click on a database and then click on "Set folder", and create your new folder:
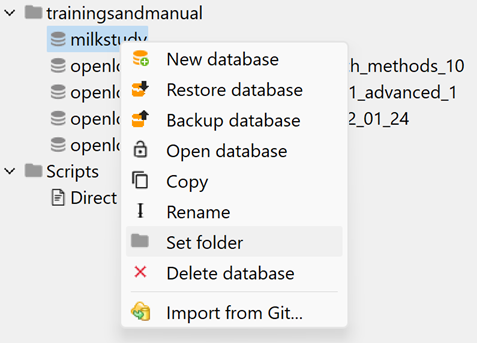
After your folder is created you can add also other databases in it just dragging and dropping them.
Note: The databases of openLCA are stored by default on C:\Users\NAME\openLCA-data-1.4 (Windows). If you are considering to change this defaul folder, follow this instruction .