Introduction
openLCA provides an API for inter-process communication (IPC) that can be used by any application written in any programming language (e.g. Python, JavaScript/TypeScript, .Net, Go, etc.)[^java_note]. This IPC protocol is provided by an openLCA server which can be a running instance of the openLCA desktop application or a web-server with an openLCA back-end that exposes this protocol. An application can connect to such an IPC server to call functions in openLCA:
+--------+ +--------------------+
| Client | <--------------> | openLCA IPC Server |
+--------+ +--------------------+
IPC - Protocol
* data management
* calculations
* result details
* ...
Starting an IPC server
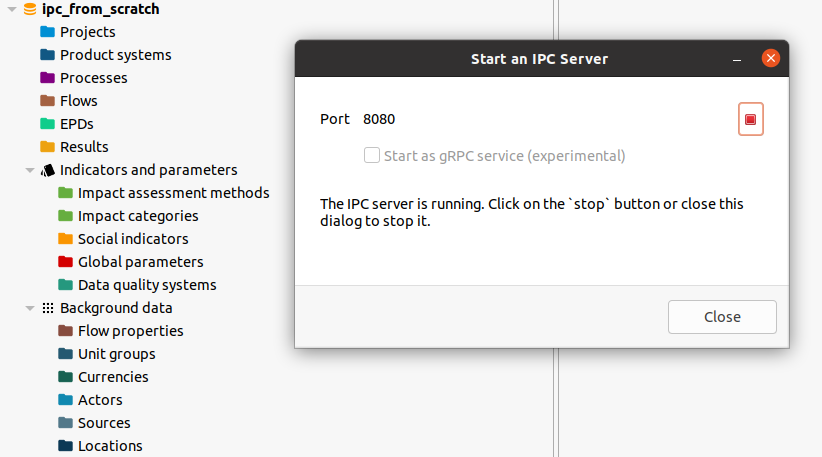
In the openLCA desktop application, you can start an IPC server for the
currently active database from the tools menu: Tools > Developer tools > IPC Server. This brings up the following dialog where you can start and stop the
server:

For headless stand-alone servers, please see the next chapter.
Available protocols
In the dialog, you can select to start a standard IPC server or a gRPC server. The standard IPC server is based on the JSON-RPC protocol provided over HTTP. This protocol is easy to implement as it is just based on JSON and HTTP. For example, it can be directly used from a web-browser using the Fetch API.
The gRPC protocol is another option, especially when you are already familiar with it or when your platform has good support for this option. In this case, you can just generate the client side interface from the openLCA service declaration.
A third option is the REST API provided by openLCA web-services. This protocol is also just based on JSON and HTTP and especially useful when integrating the openLCA back-end into web-applications.
In this documentation we try to cover all these protocols as they just provide an interface to the same service back-end of the openLCA kernel. Also, all of these protocols are based on the openLCA Schema as the data exchange format. Thus, parameter and return types in this documentation often link to their respective description in the openLCA schema documentation.
Client libraries and example applications
The table below lists some client libraries and demo applications based on the openLCA IPC protocol:
| Language | Type | Protocol | |
|---|---|---|---|
| olca-ipc.py | Python | Client library | JSON-RPC, REST |
| olca-ipc.ts | JavaScript/TypeScript | Client library | JSON-RPC, REST |
| ProtoLCA-Demo | C# | Demo | gRPC |
| protolca-js-example | JavaScript/Node | Client library | gRPC |
| olcarpc.py | Python | Client library | gRPC |
[^java_note] openLCA is a Java application and if your application is written in a language that also runs on the Java virtual machine (like Java, Kotlin, Scala, Clojure etc.) it is recommended to directly use the openLCA Java API instead of an IPC server. The kernel of openLCA can be used independently of the user interface and can be integrated as a set of standard Java libraries in JVM based applications. For example, the integrated Python editor in openLCA is in fact a Python implementation for the JVM (Jython), with which you can call the Java API of openLCA.
Stand-alone servers
As shown in the section before, it is easy to start an IPC server in openLCA
from the user interface but it is of course also possible to run these servers
as stand-alone servers. The JSON-RPC and gRPC servers are part of the openLCA
modules, the
gdt-server provides an
implementation of the Rest API of the openLCA IPC protocol. All these servers
provide a common command line interface with which a server can be configured
and started. The parameters of the configuration are listed below. All
parameters are optional. By default a server uses the default openLCA workspace
folder as used by the desktop application (~/openLCA-data-1.4) and connects to
the database with the name database in that folder:
-data <path to data folder>
The path to the data folder that contains the database and possible
libraries. The folder structure need to follow the openLCA workspace
structure, means the sub-folder `databases` of that folder contains the
database and the sub-folder `libraries` possible data libraries to which
the database is linked. If this parameter is not provided, the default
openLCA workspace (currently `~/openLCA-data-1.4`) is taken as data folder.
-db <database>
The name of the database in the data folder (only the name, not a full
file path, must be provided); defaults to 'database'.
-port <port>
The port of the server; defaults to 8080.
-native <path to native library folder>
The path to the folder from which the native libraries should be
loaded; defaults to the data folder.
-threads <number of calculation threads>
The number of parallel threads that can be used for calculations. Make sure
that the server has enough resources if you provide a larger number than 1
here; defaults to 1.
-timeout <minutes after which results are disposed>
The time in minutes after which results are cleaned up if they were not
disposed by the user. A value of <=0 means that no timeout should be
applied; defaults to 0.
--readonly <true | false>?
If this flag is set, the server will run in readonly mode and modifying the
database will not be possible.
-static <path to folder with static files>
A path to a folder with static files that should be hosted by the server.
This only has an effect if the server supports hosting of static files.
Startup scripts in openLCA
In the bin folder of the openLCA application, there are two scripts for
starting a headless IPC server (without user interface involved):
ipc-server: for JSON-RPC based IPC serversgrpc-server: for gRPC based IPC servers
These scripts just take the name of a database in the default openLCA workspace
as argument and will start a server at port 8080. For example, for Windows
starting a headless IPC server for the database ecoinvent39 looks like this:
cd openLCA\bin
.\ipc-server.cmd ecoinvent39
A running server can be quit with Ctr+c. Note that you cannot connect to a
database that is opened via the openLCA desktop application with a headless
server. You can of course modify these scripts to your needs or re-package a
server application under the respective license conditions.
Running with Docker
An IPC server can be of course also packaged as a Docker container and the gdt-server is especially useful for this. There are basically two types of gdt-server images: images with packaged LCA models (model images) and images without a model (service images).
Model images
A model image is an easy way to distribute and share one or more computable LCA
models. Such models are often parameterized and can be calculated for a given
set of parameter values on demand. Model images are typically shared as tar
archives which can be loaded into a local image repository via the load
command:
docker load -i gdt-server-{identifier}.tar
With docker image ls you should see the image then. A model image typically
does not need any configuration (timeouts, number of threads etc.), you just
run it and map the 8080 port of openLCA service in the container (note that
-d runs the container in detached mode, --rm will delete it when it is
stopped):
docker run -p 3000:8080 -d --rm gdt-server-{identifier}
In the example above, it maps the port 8080 in the container to the port
3000, the URL http://localhost:3000/api/version should then respond with the
API version of the gdt-server.
Service images
A service image contains a gdt-server and can be configured via start parameters of a container. The components of such a service image are freely available in the Github container registry and can be composed via this Dockerfile, e.g.:
cd <workdir>
curl https://raw.githubusercontent.com/GreenDelta/gdt-server/main/Dockerfile \
> Dockerfile \
&& docker build -t gdt-server .
A container can be started from such an image in the following way:
docker run \
-p 3000:8080 \
-v $HOME/openLCA-data-1.4:/app/data \
--rm -d gdt-server \
-db example --readonly
As above, it first maps the internal port to the port 3000 of the host. Also,
a data folder needs to be mounted under the /app/data folder of the container.
In this example, it maps the default openLCA workspace to that folder. More
configuration parameters can be passed to the server via the start command of
the container.
Examples
Python IPC - From scratch
In this section we will go through a complete example using the openLCA IPC interface from the olca-ipc.py Python package. As we will create everything from scratch, we first create an empty database and start an IPC server for that database:
In the Python code, we first import the required packages that we will use in
our example. The olca-schema packages comes is a dependency of the olca-ipc
package and contains the data type definitions of the openLCA model and some
utility methods. We will use Pandas for formatting our data output and NumPy,
which is a dependency of Pandas, for checking the calculation. Also, we will
add type annotations in our code, compatible with Python 3.11.
import olca_ipc as ipc
import olca_schema as o
import pandas as pd
import numpy as np
from typing import Callable
A historic example
Our example was taken from Heijungs 19941 and extended a bit. First, we define the technosphere of our system which are 4 processes connected by 4 products:
technosphere = pd.DataFrame(
data=[
[1.0, -50.0, -1.0, 0.0],
[-0.01, 1.0, -1.0, 0.0],
[0.0, 0.0, 1.0, -1.0],
[0.0, 0.0, 0.0, 100],
],
columns=[
"electricity production",
"aluminium production",
"aluminium foil production",
"sandwitch package production",
],
index=[
"electricity [MJ]",
"aluminium [kg]",
"aluminium foil [kg]",
"sandwitch package [Item(s)]",
],
)
print(technosphere)
When we print this data frame, we get the following table:
| electricity production | aluminium production | aluminium foil production | sandwitch package production | |
|---|---|---|---|---|
| electricity [MJ] | 1.00 | -50.0 | -1.0 | 0.0 |
| aluminium [kg] | -0.01 | 1.0 | -1.0 | 0.0 |
| aluminium foil [kg] | 0.00 | 0.0 | 1.0 | -1.0 |
| sandwitch package [Item(s)] | 0.00 | 0.0 | 0.0 | 100.0 |
In the rows, we have our products, in the columns the processes. Inputs have negative and outputs positive values. Thus, for 100 sandwitch packages, we would need 1 kg of aluminium foil (this is how sandwitches were packed in the 90s)2.
Next, we define the interventions of these processes with the environment:
interventions = pd.DataFrame(
data=[
[0.0, -5.0, 0.0, 0.0],
[-0.5, 0.0, 0.0, 0.0],
[3.0, 0.0, 0.0, 0.0],
[2.0, 10.0, 0.0, 1.0],
],
columns=technosphere.columns,
index=[
"bauxite [kg]",
"crude oil [kg]",
"CO2 [kg]",
"solid waste [kg]",
],
)
print(interventions)
| electricity production | aluminium production | aluminium foil production | sandwitch package production | |
|---|---|---|---|---|
| bauxite [kg] | 0.0 | -5.0 | 0.0 | 0.0 |
| crude oil [kg] | -0.5 | 0.0 | 0.0 | 0.0 |
| CO2 [kg] | 3.0 | 0.0 | 0.0 | 0.0 |
| solid waste [kg] | 2.0 | 10.0 | 0.0 | 1.0 |
In the paper, the inventory is calculated for 10 sandwitch packages as the final demand \(f\) of the system, which we can quickly do with NumPy now:
f = [
0.0,
0.0,
0.0,
10,
]
s = np.linalg.solve(technosphere.to_numpy(), f)
g = interventions.to_numpy() @ s
print(pd.DataFrame(g, index=interventions.index))
This gives the expected result:
| bauxite [kg] | -1.01 |
| crude oil [kg] | -5.10 |
| CO2 [kg] | 30.60 |
| solid waste [kg] | 22.52 |
Inventory calculations
Now we do the same in openLCA via the IPC interface. First, we create an IPC client that holds our connection data:
client = ipc.Client(8080)
As we have nothing in our database, we first need to create the units and flow properties (quantity kinds) in which the flows of the examples are measured:
mass_units = o.new_unit_group("Mass units", "kg")
energy_units = o.new_unit_group("Energy units", "MJ")
counting_units = o.new_unit_group("Counting units", "Item(s)")
mass = o.new_flow_property("Mass", mass_units)
energy = o.new_flow_property("Energy", energy_units)
count = o.new_flow_property("Number of items", counting_units)
client.put_all(
mass_units,
energy_units,
counting_units,
mass,
energy,
count,
)
While IPC server is running, you can also continue to use the openLCA user interface, just do not close the dialog of the server. When you refresh the navigation, you will see the newly created unit groups and flow properties:
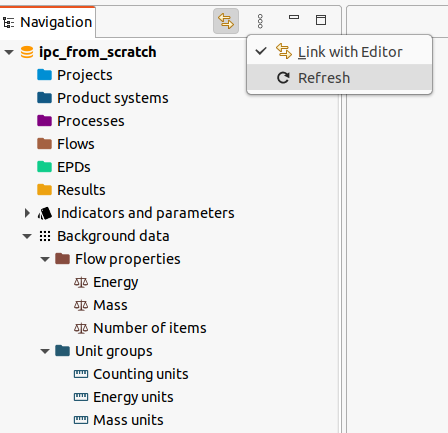
However, typically you will not create units and flow properties but use the
reference data from openLCA. For example, we can get the flow property Mass
by its name:
print(client.get(o.FlowProperty, name="Mass").to_json())
This will print the JSON serialization of that flow property which is the internal communication format of the IPC interface (and also the standard openLCA data exchange format in general):
{
"@type": "FlowProperty",
"@id": "b24a123b-f5a1-40fb-a481-afeeb50f6159",
"lastChange": "2023-01-26T13:36:37.954Z",
"name": "Mass",
"unitGroup": {
"@type": "UnitGroup",
"@id": "3e912f50-9490-473c-89fc-1393ed2eea03",
"name": "Mass units"
},
"version": "01.00.000"
}
Next, we create the flows of the example. In the snippet below, it iterates over the rows of the data frames and creates a product or elementary flow for each row, extracting the unit from the row label and mapping the corresponding flow property:
def create_flow(
row_label: str, fn: Callable[[str, o.FlowProperty], o.Flow]
) -> o.Flow:
parts = row_label.split("[")
name = parts[0].strip()
unit = parts[1][0:-1].strip()
match unit:
case "kg":
prop = mass
case "MJ":
prop = energy
case "Item(s)":
prop = count
flow = fn(name, prop)
client.put(flow)
return flow
tech_flows = [create_flow(label, o.new_product) for label in technosphere.index]
envi_flows = [
create_flow(label, o.new_elementary_flow) for label in interventions.index
]
Then we iterate over the columns of the data frames and create the corrsponding processes with their inputs and outputs of the flows we just created. One the diagonal of the technosphere matrix, the reference products of the respective processes are located and we set the these exchanges as the quantitative reference of the corresponding process:
def create_process(index: int, name: str) -> o.Process:
process = o.new_process(name)
def exchange(flow: o.Flow, value: float) -> o.Exchange | None:
if value == 0:
return None
if value < 0:
return o.new_input(process, flow, abs(value))
else:
return o.new_output(process, flow, value)
for (i, tech_flow) in enumerate(tech_flows):
value = technosphere.iat[i, index]
e = exchange(tech_flow, value)
if e and i == index:
e.is_quantitative_reference = True
for (i, envi_flow) in enumerate(envi_flows):
value = interventions.iat[i, index]
exchange(envi_flow, value)
client.put(process)
return process
processes = [
create_process(index, name)
for (index, name) in enumerate(technosphere.columns)
]
When you refresh the navigation in openLCA again, you should now see these new processes and flows:

Now we can calculate the inventory of this system. We create a calculation setup
for the sandwitch packaging process as calculation target. We do not need to set
the unit in the setup as it would take the unit of the quantitative reference of
the process by default, but we need to set the amount as we want the result for
10 sandwitches but the process has 100 as quantitative reference. The
calculation immediately returns a result object but this is maybe not ready yet,
so we wait for the calculation to be finished via the wait_until_ready
method:
setup = o.CalculationSetup(
target=o.Ref(ref_type=o.RefType.Process, id=processes[3].id),
unit=count.unit_group.ref_unit, # "Item(s)"
amount=10,
)
result = client.calculate(setup)
result.wait_until_ready()
When the result is ready, we can query the inventory from it:
inventory = result.get_total_flows()
print(
pd.DataFrame(
data=[
(
i.envi_flow.flow.name,
i.envi_flow.is_input,
i.amount,
i.envi_flow.flow.ref_unit,
)
for i in inventory
],
columns=["Flow", "Is input?", "Amount", "Unit"],
)
)
This prints the following expected values:
Flow Is input? Amount Unit
0 CO2 False 30.60 kg
1 crude oil True 5.10 kg
2 solid waste False 22.52 kg
3 bauxite True 1.01 kg
Finally, when we do not need the result anymore, we need to dispose it so that allocated resources can be freed on the openLCA side:
result.dispose()
Full workbook
Below is the full example. Note that you can run it as a note-book, cell by cell, in VS Code:
# %%
# ANCHOR: imports
import olca_ipc as ipc
import olca_schema as o
import pandas as pd
import numpy as np
from typing import Callable
# ANCHOR_END: imports
# %%
# ANCHOR: techsphere
technosphere = pd.DataFrame(
data=[
[1.0, -50.0, -1.0, 0.0],
[-0.01, 1.0, -1.0, 0.0],
[0.0, 0.0, 1.0, -1.0],
[0.0, 0.0, 0.0, 100],
],
columns=[
"electricity production",
"aluminium production",
"aluminium foil production",
"sandwitch package production",
],
index=[
"electricity [MJ]",
"aluminium [kg]",
"aluminium foil [kg]",
"sandwitch package [Item(s)]",
],
)
print(technosphere)
# ANCHOR_END: techsphere
# %%
# ANCHOR: envisphere
interventions = pd.DataFrame(
data=[
[0.0, -5.0, 0.0, 0.0],
[-0.5, 0.0, 0.0, 0.0],
[3.0, 0.0, 0.0, 0.0],
[2.0, 10.0, 0.0, 1.0],
],
columns=technosphere.columns,
index=[
"bauxite [kg]",
"crude oil [kg]",
"CO2 [kg]",
"solid waste [kg]",
],
)
print(interventions)
# ANCHOR_END: envisphere
# %%
# ANCHOR: numsol
f = [
0.0,
0.0,
0.0,
10,
]
s = np.linalg.solve(technosphere.to_numpy(), f)
g = interventions.to_numpy() @ s
print(pd.DataFrame(g, index=interventions.index))
# ANCHOR_END: numsol
# %%
# ANCHOR: mkclient
client = ipc.Client(8080)
# ANCHOR_END: mkclient
# %%
# ANCHOR: units
mass_units = o.new_unit_group("Mass units", "kg")
energy_units = o.new_unit_group("Energy units", "MJ")
counting_units = o.new_unit_group("Counting units", "Item(s)")
mass = o.new_flow_property("Mass", mass_units)
energy = o.new_flow_property("Energy", energy_units)
count = o.new_flow_property("Number of items", counting_units)
client.put_all(
mass_units,
energy_units,
counting_units,
mass,
energy,
count,
)
# ANCHOR_END: units
# %%
# ANCHOR: mass
print(client.get(o.FlowProperty, name="Mass").to_json())
# ANCHOR_END: mass
# %%
# ANCHOR: flows
def create_flow(
row_label: str, fn: Callable[[str, o.FlowProperty], o.Flow]
) -> o.Flow:
parts = row_label.split("[")
name = parts[0].strip()
unit = parts[1][0:-1].strip()
match unit:
case "kg":
prop = mass
case "MJ":
prop = energy
case "Item(s)":
prop = count
flow = fn(name, prop)
client.put(flow)
return flow
tech_flows = [create_flow(label, o.new_product) for label in technosphere.index]
envi_flows = [
create_flow(label, o.new_elementary_flow) for label in interventions.index
]
# ANCHOR_END: flows
# %%
# ANCHOR: processes
def create_process(index: int, name: str) -> o.Process:
process = o.new_process(name)
def exchange(flow: o.Flow, value: float) -> o.Exchange | None:
if value == 0:
return None
if value < 0:
return o.new_input(process, flow, abs(value))
else:
return o.new_output(process, flow, value)
for (i, tech_flow) in enumerate(tech_flows):
value = technosphere.iat[i, index]
e = exchange(tech_flow, value)
if e and i == index:
e.is_quantitative_reference = True
for (i, envi_flow) in enumerate(envi_flows):
value = interventions.iat[i, index]
exchange(envi_flow, value)
client.put(process)
return process
processes = [
create_process(index, name)
for (index, name) in enumerate(technosphere.columns)
]
# ANCHOR_END: processes
# %%
# ANCHOR: calc
setup = o.CalculationSetup(
target=o.Ref(ref_type=o.RefType.Process, id=processes[3].id),
unit=count.unit_group.ref_unit, # "Item(s)"
amount=10,
)
result = client.calculate(setup)
result.wait_until_ready()
# ANCHOR_END: calc
# %%
# ANCHOR: inventory
inventory = result.get_total_flows()
print(
pd.DataFrame(
data=[
(
i.envi_flow.flow.name,
i.envi_flow.is_input,
i.amount,
i.envi_flow.flow.ref_unit,
)
for i in inventory
],
columns=["Flow", "Is input?", "Amount", "Unit"],
)
)
# ANCHOR_END: inventory
# %%
# ANCHOR: free-inventory
result.dispose()
# ANCHOR_END: free-inventory
# %%
Reinout Heijungs: A generic method for the identification of options for cleaner products. Ecological Economics, Volume 10, Issue 1, 1994, Pages 69-81, ISSN 0921-8009, https://doi.org/10.1016/0921-8009(94)90038-8.
it is of course just an illustrative example and not real data
Calculation parameters
This example shows the calculation of an LCA model with different parameter
values. We will use the openLCA Python IPC module and the REST API in this
example. First, we need to make sure that the current olca-ipc package is
installed. Currently the latest
version for openLCA 2 is 2.0.0a4:
pip install olca-ipc==2.0.0a4
We connect to a REST API in this example and assume that it is running at
http://192.168.142.136:3000
import olca_schema as o
import olca_ipc.rest as rest
import json
client = rest.RestClient("http://192.168.142.136:3000")
To check that we can access the server, we can also just call this URL in a
browser: http://192.168.142.136:3000/api/version, which should then return the
API version of that server.
Next, we check which models (product systems) are available and select the first model for our calculations:
models = client.get_descriptors(o.ProductSystem)
for model in models:
print(f"{model.name} :: {model.id}")
model = models[0]
This should print something like this depending on the available models:
battery model without EoL :: 59327d11-9a0d-477b-9cc0-060ca74b6327
battery model with EoL :: eb31db8a-8102-453d-a549-be989e83c592
Again, we could just query an URL for this, for the example:
http://192.168.142.136:3000/data/product-systems
We do the same for the available impact assessment methods (
http://192.168.142.136:3000/data/methods):
methods = client.get_descriptors(o.ImpactMethod)
for method in methods:
print(f"{method.name} :: {method.id}")
method = methods[0]
This should print something like this:
EF 3.0 Method (adapted) :: b4571628-4b7b-3e4f-81b1-9a8cca6cb3f8
...
With the reference to a product system and LCIA method, we can create a calculation setup:
setup = o.CalculationSetup(
target=model,
impact_method=method,
)
print(json.dumps(setup.to_dict(), indent=2))
The objects of the openLCA schema can be easily translated to JSON as done in the snippet above. This is the payload that is posted to the server in a calculation request:
{
"impactMethod": {
"@type": "ImpactMethod",
"@id": "b4571628-4b7b-3e4f-81b1-9a8cca6cb3f8",
"category": "openLCA LCIA methods 2_1_2",
"name": "EF 3.0 Method (adapted)"
},
"target": {
"@type": "ProductSystem",
"@id": "59327d11-9a0d-477b-9cc0-060ca74b6327",
"name": "battery model without EoL"
}
}
We can calculate the setup like this:
result = client.calculate(setup)
result.wait_until_ready()
impacts = result.get_total_impacts()
for i in impacts:
assert i.impact_category
print(f"{i.impact_category.name} {i.amount} {i.impact_category.ref_unit}")
result.dispose()
As shown above, we should dispose a result when we do not need it anymore. The snippet prints something like:
...
Climate change 0.7891638059816873 kg CO2 eq
...
For parameterized models, the default parameter values are applied in a calculation but we can change them in each calculation. We can query the parameters of a model like this:
parameters = client.get_parameters(o.ProductSystem, model.id)
for param in parameters:
print(f"parameter: {param.name} = {param.value}")
param = parameters[0]
For our example, we just have a single parameter, number_of_recharges with
a default value of 1.0:
parameter: number_of_recharges = 1.0
The corresponding URL is:
http://192.168.142.136:3000/data/product-systems/59327d11-9a0d-477b-9cc0-060ca74b6327/parameters
Finally, we run a set of calculations over a parameter range:
for x in range(0, 55, 5):
setup = o.CalculationSetup(
target=model,
impact_method=method,
parameters=[
o.ParameterRedef(name=param.name, value=x, context=param.context)
],
)
result = client.calculate(setup)
assert result
result.wait_until_ready()
impacts = result.get_total_impacts()
for i in impacts:
if i.impact_category.name == "Climate change":
print(f"{param.name}: {x} => {i.amount : .3f} kg CO2 eq")
result.dispose()
For the example, it prints something like this:
number_of_recharges: 0 => 0.788 kg CO2 eq
number_of_recharges: 5 => 0.792 kg CO2 eq
number_of_recharges: 10 => 0.796 kg CO2 eq
number_of_recharges: 15 => 0.800 kg CO2 eq
number_of_recharges: 20 => 0.803 kg CO2 eq
number_of_recharges: 25 => 0.807 kg CO2 eq
number_of_recharges: 30 => 0.811 kg CO2 eq
number_of_recharges: 35 => 0.814 kg CO2 eq
number_of_recharges: 40 => 0.818 kg CO2 eq
number_of_recharges: 45 => 0.822 kg CO2 eq
number_of_recharges: 50 => 0.826 kg CO2 eq
Data management
The openLCA IPC protocol is based on the openLCA Schema as data exchange format. Thus, parameter and return types of this documentation often link to their respective description in the openLCA schema documentation. The openLCA schema is a typed data format with the following principles:
- There are stand-alone entities like processes or flows, called root entities, and composition entities that can only exist within another entity, like the inputs and outputs (called exchanges) of a process.
- There is a uniform reference concept in the format: if an entity
Areferences an entityBit only stores a reference toBthat is of type Ref. This reference contains the type (if it cannot be inferred from field inA), the ID, and some optional meta-data ofB.
+---+ Ref +---+
| A | ----> | B |
+---+ +---+
For example, an output in a process is of type Exchange and an exchange contains a reference to a flow. In addition, instances of the Ref type are often used as data set descriptors: instead of loading the full data set it is often enough to just display some meta-data of an entity (for example in search results).
Many of the data management functions are the same for all root entity types. Thus, the respective type is often just an additional parameter of a method call. The table below shows the root entity types and their parameter value in the Rest API (multiple values can map to the same type for convenience):
| Root entity type | Rest parameter |
|---|---|
| Actor | actor, actors |
| Category | category, categories |
| Currency | currency, currencies |
| DQSystem | dq-system, dq-systems |
| Epd | epd, epds |
| Flow | flow, flows |
| FlowProperty | flow-property, flow-properties |
| ImpactCategory | impact-category, impact-categories |
| ImpactMethod | impact-method, method, impact-methods, methods |
| Location | location, locations |
| Parameter | parameter, parameters |
| Process | process, processes |
| ProductSystem | product-system, product-systems, model, models |
| Project | project, projects |
| Result | result, results |
| SocialIndicator | social-indicator, social-indicators |
| Source | source, sources |
| UnitGroup | unit-group, unit-groups |
Get descriptors
This function is useful for exploring the content of a database. It returns a list of data set descriptors for a given data set type. A descriptor contains just a few information, like the name or category path, to understand the content of a data set. Descriptors are valid data set references; they can be used to reference a data set in a given context (e.g. referencing a process as calculation target in a calculation setup).
| Rest API | GET /data/{type} |
| JSON-RPC | data/get/descriptors |
| Python/IPC | Client.get_descriptors |
| Return type | List[Ref] |
Examples
Python IPC
import olca_ipc as ipc
import olca_schema as o
client = ipc.Client()
refs = client.get_descriptors(o.FlowProperty)
for ref in refs:
print(ref.name)
# Area
# Area*time
# Duration
# Energy
JSON-RPC via Fetch API
The example below shows the usage of this method using the JSON-RPC protocol via the Fetch API which is available in modern web-browsers or platforms like Deno.
let resp = await fetch("http://localhost:8080", {
method: "POST",
body: JSON.stringify({
jsonrpc: "2.0",
id: 1,
method: "data/get/descriptors",
params: {
"@type": "FlowProperty"
}
})
});
let descriptors = await resp.json();
console.log(descriptors);
// {
// jsonrpc: "2.0",
// id: 1,
// result: [
// {
// "@type": "FlowProperty",
// "@id": "838aaa20-0117-11db-92e3-0800200c9a66",
// name: "Goods transport (mass*distance)",
// category: "Technical flow properties",
// refUnit: "t*km"
// },
Get a full data set by ID
This method returns the full data set of a given type and ID.
| Rest API | GET /data/{type}/{id} |
| JSON-RPC | data/get |
| Python/IPC | Client.get |
| Return type | E > RootEntity |
Examples
Python IPC
import olca_ipc as ipc
import olca_schema as o
client = ipc.Client()
process = client.get(o.Process, "eacc4872-6f4e-4ff1-946e-c1bddeda24be")
print(process)
# Process(
# id='eacc4872-6f4e-4ff1-946e-c1bddeda24be',
# exchanges=[Exchange(amount=1.0, flow=Ref(id='b254bbdf- ...
JSON-RPC via Fetch API
The example below shows the usage of this method using the JSON-RPC protocol via the Fetch API which is available in modern web-browsers or platforms like Deno.
let resp = await fetch("http://localhost:8080", {
method: "POST",
body: JSON.stringify({
jsonrpc: "2.0",
id: 1,
method: "data/get",
params: {
"@type": "Process",
"@id": "eacc4872-6f4e-4ff1-946e-c1bddeda24be"
}
})
});
let v = await resp.json();
console.log(v);
// {
// jsonrpc: "2.0",
// result: {
// "@type": "Process",
// "@id": "eacc4872-6f4e-4ff1-946e-c1bddeda24be",
// name: "blast furnace gas, Recycled Content cut-off",
// processType: "LCI_RESULT",
Curl
endpoint="http://localhost:8080"
process_id="eacc4872-6f4e-4ff1-946e-c1bddeda24be"
curl "$endpoint/data/process/$process_id"
# { "@type":"Process",
# "@id":"eacc4872-6f4e-4ff1-946e-c1bddeda24be",
# "name":"blast furnace gas, Recycled Content cut-off
Get a full data set by name
This method returns a full data set for the given type and name. Note that the name does not have to be unique in an openLCA database, and in this case, it will just return the first entity from the database with the given name.
| Rest API | GET /data/{type}/name/{name} |
| JSON-RPC | data/get |
| Python/IPC | Client.get |
| Return type: | E > RootEntity |
Examples
Python IPC
import olca_ipc as ipc
import olca_schema as o
client = ipc.Client()
mass = client.get(o.FlowProperty, name="Mass")
print(mass)
# FlowProperty(
# name='Mass',
# id='93a60a56-a3c8-11da-a746-0800200b9a66',
# unit_group=Ref(id='93a60a57-a4c8-11da-a746-0800200c9a66', ...
JSON-RPC via Fetch API
The example below shows the usage of this method using the JSON-RPC protocol via the Fetch API which is available in modern web-browsers or platforms like Deno.
let resp = await fetch("http://localhost:8080", {
method: "POST",
body: JSON.stringify({
jsonrpc: "2.0",
id: 1,
method: "data/get",
params: {
"@type": "FlowProperty",
"name": "Mass",
}
})
});
let v = await resp.json();
console.log(v);
// {
// jsonrpc: "2.0",
// result: {
// "@type": "FlowProperty",
// "@id": "93a60a56-a3c8-11da-a746-0800200b9a66",
// name: "Mass",
// category: "Technical flow properties",
// version: "00.00.000",
// flowPropertyType: "PHYSICAL_QUANTITY",
Get the descriptor of a data set
Returns the descriptor of the data set with the given type and ID.
| Rest API | GET /data/{type}/{id}/info |
| JSON-RPC | data/get/descriptor |
| Python/IPC | Client.get_descriptor |
| Return type: | Ref |
Examples
Python IPC
import olca_ipc as ipc
import olca_schema as o
client = ipc.Client()
mass_ref = client.get_descriptor(o.FlowProperty, name="Mass")
print(mass_ref)
# Ref(
# id='93a60a56-a3c8-11da-a746-0800200b9a66',
# category='Technical flow properties',
# name='Mass',
# ...
JSON-RPC via Fetch API
The example below shows the usage of this method using the JSON-RPC protocol via the Fetch API which is available in modern web-browsers or platforms like Deno.
let resp = await fetch("http://localhost:8080", {
method: "POST",
body: JSON.stringify({
jsonrpc: "2.0",
id: 1,
method: "data/get/descriptor",
params: {
"@type": "Process",
"@id": "eacc4872-6f4e-4ff1-946e-c1bddeda24be",
}
})
});
let v = await resp.json();
console.log(v);
// {
// jsonrpc: "2.0",
// id: 1,
// result: {
// "@type": "Process",
// "@id": "eacc4872-6f4e-4ff1-946e-c1bddeda24be",
// name: "blast furnace gas, Recycled Content cut-off",
// processType: "LCI_RESULT",
// flowType: "PRODUCT_FLOW"
// }
// }
Get all data sets of a given type
Returns all data sets of a given type from a database. This is not a practical method for all types of data sets and may is not available in a specific context. For example, it is fine to get all unit groups but a server would go down when you query for all processes in a large database. Typically, you just want to query all descriptors of a data set type.
| Rest API | GET /data/{type}/all |
| JSON-RPC | data/get/all |
| Python IPC | Client.get_all |
| Return type: | List[E > RootEntity] |
Examples
Python IPC
import olca_ipc as ipc
import olca_schema as o
client = ipc.Client()
for group in client.get_all(o.UnitGroup):
print(group.name)
# Units of area
# Units of energy
# Units of length
# Units of mass
# ...
JSON-RPC via Fetch API
The example below shows the usage of this method using the JSON-RPC protocol via the Fetch API which is available in modern web-browsers or platforms like Deno.
let resp = await fetch("http://localhost:8080", {
method: "POST",
body: JSON.stringify({
jsonrpc: "2.0",
id: 1,
method: "data/get/all",
params: {
"@type": "UnitGroup"
}
})
});
let v = await resp.json();
console.log(v);
// {
// jsonrpc: "2.0",
// result: [
// {
// "@type": "UnitGroup",
// "@id": "838aaa21-0117-11db-92e3-0800200c9a66",
// name: "Units of mass*length",
// category: "Technical unit groups",
// version: "00.00.000",
// defaultFlowProperty: {
Get the parameters of a data set
Returns the (local) parameters of the specified data set. In case of processes and impact categories, a list of parameters is returned. For product systems, the respective parameter redefinitions are returned.
| Rest API | GET /data/{type}/{id}/parameters |
| JSON-RPC | data/get/parameters |
| Python/IPC | Client.get_parameters |
| Return type | * |
*Return type:
List[Parameter]for processes and impact categoriesList[ParameterRedef]for product systems
Examples
Python IPC
import olca_ipc as ipc
import olca_schema as o
client = ipc.Client()
params = client.get_parameters(
o.ProductSystem, "0db1eda6-a34e-4c82-b06b-19f27c92495a"
)
for p in params:
print(f"{p.name}: {p.value}")
# param1: 42
# param2: 21
# ...
JSON-RPC via Fetch API
The example below shows the usage of this method using the JSON-RPC protocol via the Fetch API which is available in modern web-browsers or platforms like Deno.
let resp = await fetch("http://localhost:8080", {
method: "POST",
body: JSON.stringify({
jsonrpc: "2.0",
id: 1,
method: "data/get/parameters",
params: {
"@type": "ProductSystem",
"@id": "0db1eda6-a34e-4c82-b06b-19f27c92495a",
}
})
});
let v = await resp.json();
console.log(v);
// {
// jsonrpc: "2.0",
// result: [
// { name: "param_a", value: 994, isProtected: false },
// { name: "param_b", value: 0.7237, isProtected: false },
// { name: "param_c", value: 0, isProtected: false },
Get providers of technosphere flows
Technosphere flows are products or waste flows that can be linked in a product system model. For products, the providers are processes that produce this product as output. For waste flows, providers are waste treatment processes with an input of that waste flow. These provider and flow pairs can be linked to product inputs and waste outputs of other processes in a product system.
| Rest API | GET /data/providers |
| JSON-RPC | data/get/providers |
| Python IPC | Client.get_providers |
| Return type: | List[TechFlow] |
Examples
Python IPC
import olca_ipc as ipc
client = ipc.Client()
for p in client.get_providers()[:5]:
print(p)
# TechFlow(
# provider=Ref(id='71dab7ae-4d58-4f73-8449-5967c296bcde', ...
# flow=Ref(id='7f6bb533-2d3c-43a6-ac60-6eef299d7c52', ...
JSON-RPC via Fetch API
The example below shows the usage of this method using the JSON-RPC protocol via the Fetch API which is available in modern web-browsers or platforms like Deno.
let resp = await fetch("http://localhost:8080", {
method: "POST",
body: JSON.stringify({
jsonrpc: "2.0",
id: 1,
method: "data/get/providers",
})
});
let v = await resp.json();
console.log(v);
// {
// jsonrpc: "2.0",
// result: [
// {
// provider: {
// "@type": "Process",
// "@id": "ba98a130-d92c-4c40-8fe9-c8cab5b956ab",
// name: "electricity production, wind, 1-3MW turbine, onshore",
// processType: "LCI_RESULT",
// flowType: "PRODUCT_FLOW"
// },
Get providers for a flow
This method returns the processes that produce a given product (as output) or provide the treatment of a given waste flow (as input). Thus, the flow parameter of this method needs to be a product or waste flow (or an ID of that flow). The returned providers can be linked to respective product inputs or waste outputs of other processes in a product system.
| Rest API | GET /data/providers/{flow-id} |
| JSON-RPC | data/get/providers |
| Python IPC | Client.get_providers |
| Return type: | List[TechFlow] |
Examples
Python IPC
import olca_ipc as ipc
import olca_schema as o
client = ipc.Client()
providers = client.get_providers(
flow=o.Ref(id="7f6bb533-2d3c-43a6-ac60-6eef299d7c52")
)
for p in providers:
print(p)
# TechFlow(
# provider=Ref(id='71dab7ae-4d58-4f73-8449-5967c296bcde', ...
# flow=Ref(id='7f6bb533-2d3c-43a6-ac60-6eef299d7c52', ...
JSON-RPC via Fetch API
The example below shows the usage of this method using the JSON-RPC protocol via the Fetch API which is available in modern web-browsers or platforms like Deno.
let resp = await fetch("http://localhost:8080", {
method: "POST",
body: JSON.stringify({
jsonrpc: "2.0",
id: 1,
method: "data/get/providers",
params: {
// only the ID is required here
"@type": "Flow",
"@id": "66c93e71-f32b-4591-901c-55395db5c132",
name: "electricity, high voltage"
}
})
});
let v = await resp.json();
console.log(v);
// {
// jsonrpc: "2.0",
// result: [
// {
// provider: {
// "@type": "Process",
// "@id": "ba98a130-d92c-4c40-8fe9-c8cab5b956ab",
// name: "electricity production, wind, 1-3MW turbine, onshore",
// processType: "LCI_RESULT",
// flowType: "PRODUCT_FLOW"
// },
Insert or update a data set
Inserts or updates a provided data set in the database. This method is not available when a server runs in read-only mode.
| Rest API | PUT /data/{type} |
| JSON-RPC | data/put |
| Python/IPC | client.put |
| Request body | E > RootEntity |
| Return type: | Ref |
Examples
Python IPC
import olca_ipc as ipc
import olca_schema as o
client = ipc.Client()
ref = client.put(o.Source(name="Inter-process communication with openLCA"))
print(ref)
# Ref(
# id="16cba9b2-2987-4735-9f3e-96fedf8449dd",
# name="Inter-process communication with openLCA",
# ...
JSON-RPC via Fetch API
The example below shows the usage of this method using the JSON-RPC protocol via the Fetch API which is available in modern web-browsers or platforms like Deno.
let resp = await fetch("http://localhost:8080", {
method: "POST",
body: JSON.stringify({
jsonrpc: "2.0",
id: 1,
method: "data/put",
params: {
"@type": "Source",
"@id": "91bbc461-4ce1-4f83-b95d-de0909575174",
"name": "Inter-process communication with openLCA",
// ...
}
})
});
let v = await resp.json();
console.log(v);
// {
// jsonrpc: "2.0",
// id: 1,
// result: {
// "@type": "Source",
// "@id": "91bbc461-4ce1-4f83-b95d-de0909575174",
// name: "Inter-process communication with openLCA"
// }
// }
Create a product system
This method creates a product system for a given process. It recursively links the processes of that system according to the given linking configuration.
| Rest API | GET /data/{type}/all |
| JSON-RPC | data/get/all |
| Python IPC | Client.get_all |
| Parameter | Ref[Process] |
| Parameter | LinkingConfig |
| Return type: | Ref[ProductSystem] |
Examples
Python IPC
import olca_ipc as ipc
import olca_schema as o
client = ipc.Client()
process_ref = client.find(o.Process, "aluminium foil production")
config = o.LinkingConfig(
prefer_unit_processes=True,
provider_linking=o.ProviderLinking.PREFER_DEFAULTS,
)
system_ref = client.create_product_system(process_ref, config)
print(f"created product system {system_ref.name}, id={system_ref.id}")
# created product system aluminium foil production, id=fbc33e47-ee...
Delete a data set
Deletes the specified data set from the database. This method is not available when the server runs in read-only mode.
| Rest API | DELETE /data/{type}/{id} |
| JSON-RPC | data/delete |
| Python/IPC | Client.delete |
| Return type: | Ref |
Examples
Python IPC
import olca_ipc as ipc
import olca_schema as o
client = ipc.Client()
ref = client.delete(
o.Ref(ref_type=o.RefType.Source, id="16cba9b2-2987-4735-9f3e-96fedf8449dd")
)
print(ref)
# Ref(
# id="16cba9b2-2987-4735-9f3e-96fedf8449dd",
# name="Inter-process communication with openLCA",
# ...
JSON-RPC via Fetch API
The example below shows the usage of this method using the JSON-RPC protocol via the Fetch API which is available in modern web-browsers or platforms like Deno.
let resp = await fetch("http://localhost:8080", {
method: "POST",
body: JSON.stringify({
jsonrpc: "2.0",
id: 1,
method: "data/delete",
params: {
"@type": "Source",
"@id": "91bbc461-4ce1-4f83-b95d-de0909575174",
}
})
});
let v = await resp.json();
console.log(v);
// {
// jsonrpc: "2.0",
// result: {
// "@type": "Source",
// "@id": "91bbc461-4ce1-4f83-b95d-de0909575174",
Calculation and results
When starting a calculation, it is first scheduled in a calculation queue. This
is because multiple calculations could be started at the same time and
calculations may need to wait for other calculations first to be finished. Thus,
a calculation directly returns a
ResultState
object with a unique identifier. With this identifier, the state of the
calculation can be retrieved from the server. It is then also the ID of the
corresponding result when the calculation is finished. When a result is not
needed anymore, the dispose method should be called so that the allocated
resources of the result can be released.
The idea of the result interface is not to provide some ready-to-use charts and tables but to provide all possible building blocks with which such higher level result views can be created (charts, tables, upstream trees, Sankey diagrams). Thus, the result interface has many methods that often look quite similar but they have their purpose for efficiently creating higher level result views.
Result elements
Depending on the calculation setup and the calculated model, results can be retrieved for different elements, these are:
- Technosphere flows,
tech-flows: the product and waste flows of the product system with their corresponding providers. - Intervention flows,
envi-flows: typically elementary flows but also unconnected product or waste inputs or outputs of the processes in the system. These flows cross the boundary to the environment of the system and form the inventory result of the system. In case of a regionalized calculation, an intervention flow is a pair of flow and location. - Impact categories,
impact-categories: the impact categories of the impact assessment method selected in the calculation setup. - costs: life cycle costs
Technosphere flows are always present. All other result elements are only available if the calculated model provides these elements and/or if the corresponding options are set in the calculation setup.
Mathematical relations
Where possible, a short formula for calculating a respective result is provided in the following documentation of the respective functions. These formulas are based on standard matrix algebra for LCA computations. However, this does not mean that a respective result is calculated by exactly using this formula.
Calculate results
This method schedules a new calculation for a given setup. It directly returns
a state object that contains the result ID (field @id). With this ID the
the result state can be queried.
| REST | POST result/calculate |
| IPC | result/calculate |
| Python IPC | Client.calculate |
| Return type | ResultState |
| Parameter type | CalculationSetup |
Examples
Python IPC
import olca_ipc as ipc
import olca_schema as o
# create a calculation setup
setup = o.CalculationSetup(
target=o.Ref(
ref_type=o.RefType.ProductSystem,
id="0db1eda6-a34e-4c82-b06b-19f27c92495a",
),
impact_method=o.Ref(id="b4571628-4b7b-3e4f-81b1-9a8cca6cb3f8"),
nw_set=o.Ref(id="867fe119-0b5c-38a0-a3e6-1d845ffaedd5"),
)
# run a calculation
client = ipc.Client()
result: ipc.Result = client.calculate(setup)
JSON-RPC via Fetch API
The example below shows the usage of this method using the JSON-RPC protocol via the Fetch API which is available in modern web-browsers or platforms like Deno.
let resp = await fetch("http://localhost:8080", {
method: "POST",
body: JSON.stringify({
jsonrpc: "2.0",
id: 1,
method: "result/calculate",
params: {
target: {
"@type": "ProductSystem",
"@id": "0db1eda6-a34e-4c82-b06b-19f27c92495a"
},
impactMethod: {
"@id": "b4571628-4b7b-3e4f-81b1-9a8cca6cb3f8",
},
nwSet: {
"@id": "867fe119-0b5c-38a0-a3e6-1d845ffaedd5",
},
withCosts: true,
amount: 1.0
}
})
});
let v = await resp.json();
console.log(v);
// {
// jsonrpc: "2.0",
// result: {
// "@id": "e316a369-bf5b-4c25-a61f-3492cfca9535",
// isReady: false,
// isScheduled: true,
// time: 1671187585187
// },
// id: 1
// }
Get state
This method returns the result state of a calculation. When a calculation is started, it is
scheduled in a calculation queue first. The calculation directly returns a result state with
a unique ID (field @id) of the result. Only when the state of a result is ready, calculation
results can be retrieved.
| API | Method |
|---|---|
| REST | GET result/{result-id}/state |
| IPC | result/state |
| Python IPC | Result.get_state |
| Return type | ResultState |
Examples
Python IPC
state = result.get_state()
if state.error:
print(f"calculation failed: {state.error}")
exit(-1)
# actively waiting for a result
import time
while not result.get_state().is_ready:
time.sleep(1)
print("waiting ...")
# or better do this:
state = result.wait_until_ready()
print(f"result id: {state.id}")
JSON-RPC via Fetch API
The example below shows the usage of this method using the JSON-RPC protocol via the Fetch API which is available in modern web-browsers or platforms like Deno.
let resp = await fetch("http://localhost:8080", {
method: "POST",
body: JSON.stringify({
jsonrpc: "2.0",
id: 1,
method: "result/state",
params: {
"@id": "e316a369-bf5b-4c25-a61f-3492cfca9535",
}
})
});
let v = await resp.json();
console.log(v);
// {
// jsonrpc: "2.0",
// result: {
// "@id": "e316a369-bf5b-4c25-a61f-3492cfca9535",
// isReady: true,
// isScheduled: false,
// time: 1671187586993
// },
// id: 1
// }
Dispose result
This method should be always called when a result is not needed anymore. It disposes the result and releases allocated resources of that result.
| API | Method |
|---|---|
| REST | POST result/{result-id}/dispose |
| IPC | result/dispose |
| Python IPC | Result.dispose |
| Return type | ResultState |
Examples
Python IPC
# it is important to dispose a result when it is not needed anymore
result.dispose()
JSON-RPC via Fetch API
The example below shows the usage of this method using the JSON-RPC protocol via the Fetch API which is available in modern web-browsers or platforms like Deno.
let resp = await fetch("http://localhost:8080", {
method: "POST",
body: JSON.stringify({
jsonrpc: "2.0",
id: 1,
method: "result/dispose",
params: {
"@id": "e316a369-bf5b-4c25-a61f-3492cfca9535",
}
})
});
let v = await resp.json();
console.log(v);
// {
// jsonrpc: "2.0",
// result: {
// "@id": "e316a369-bf5b-4c25-a61f-3492cfca9535"
// },
// id: 1
// }
Monte Carlo Simulations
Running a Monte Carlo Simulation is similar to a normal calculation. You first
call the simulate method with a calculation setup. This schedules a first
simulation run. When the calculation is ready, the result can be queried like
any other result. For each subsequent iteration you call the next method on
that result which schedules a new iteration, that again returns a result that
can be queried, and so on. Old iteration results are disposed automatically when
a new iteration is started but you should dispose the last result when it is not
needed anymore.
The API method for the first iteration is:
| REST | POST result/simulate |
| IPC | result/simulate |
| Python IPC | Client.simulate |
| Return type | ResultState |
| Parameter type | CalculationSetup |
For each subsequent calculation, the API method is:
| REST | POST result/{result-id}/simulate/next |
| IPC | result/simulate/next |
| Python IPC | Result.simulate_next |
| Return type | ResultState |
| Parameter type | result id |
Examples
Python IPC
import random as rand
import statistics as stats
import olca_ipc as ipc
import olca_schema as o
client = ipc.Client()
# schedule a first iteration
print("run iteration 1")
result = client.simulate(
o.CalculationSetup(
target=o.Ref(
ref_type=o.RefType.ProductSystem,
id="7d1cbce0-b5b3-47ba-95b5-014ab3c7f569",
),
impact_method=o.Ref(id="99b9d86b-ec6f-4610-ba9f-68ebfe5691dd"),
)
)
result.wait_until_ready()
# get the result for some indicator from the first iteration
indicator = rand.choice(result.get_impact_categories())
val = lambda: result.get_total_impact_value_of(indicator).amount
xs: list[float] = [val()]
# collect the values from 99 more iterations
for i in range(0, 99):
print(f"run iteration {i+2}")
result.simulate_next()
result.wait_until_ready()
xs.append(val())
result.dispose()
# plot the results in a simple histogram
bucket_count = 15
quantiles = stats.quantiles(xs, n=bucket_count + 1, method="inclusive")
buckets = [0] * bucket_count
for x in xs:
bucket = 0
for i in range(1, bucket_count):
if x <= quantiles[i]:
bucket += 1
buckets[bucket] += 1
for i in buckets:
print(f"|{'#' * i}")
# ...
# run iteration 98
# run iteration 99
# run iteration 100
#
# |#######
# |######
# |######
# |######
# |######
# |#######
# |######
# |######
# |######
# |######
# |#######
# |######
# |######
# |######
# |#############
Technosphere flows
This method returns the \(n\) technosphere flows of a result. These are the flows by which the processes of the calculated system are linked. Each technosphere flow is a pair of a product or waste flow and a provider where the provider is typically a process but can also be a product system (a sub-system) or even another result. The technosphere matrix \(A\) is symmetrically indexed by these technosphere flows:
$$ A \in \mathbb{R}^{n \times n} $$
| REST | result/{result-id}/tech-flows |
| IPC | result/tech-flows |
| Python IPC | Result.get_tech_flows |
| Return type | List[TechFlow] |
Examples
Python IPC
tech_flows = result.get_tech_flows()
print(
pd.DataFrame(
[
(tf.provider.name, tf.flow.name, tf.flow.ref_unit)
for tf in tech_flows
],
columns=["Provider", "Flow", "Unit"],
).head()
)
# Provider Flow Unit
# 0 Fresh wheat, corn, rice, and oth... Fresh wheat, corn, ric... USD
# 1 Synthetic dyes and pigments... Synthetic dyes an... USD
# 2 Cardboard containers... Cardboard ... USD
# 3 Synthetic rubber and artificial ... Synthetic rubber and a... USD
# 4 Packaged poultry... Packag... USD
JSON-RPC via Fetch API
The example below shows the usage of this method using the JSON-RPC protocol via the Fetch API which is available in modern web-browsers or platforms like Deno.
let resp = await fetch("http://localhost:8080", {
method: "POST",
body: JSON.stringify({
jsonrpc: "2.0",
id: 1,
method: "result/tech-flows",
params: {
"@id": "77ccaffa-9d79-4f38-8da5-4413469b8a7b",
}
})
});
let v = await resp.json();
console.log(v);
// {
// jsonrpc: "2.0",
// id: 1,
// result: [
// {
// provider: {
// "@type": "Process",
// "@id": "7c619276-7b15-472a-b261-0110d461755a",
// name: "market for natural gas, high pressure",
// processType: "LCI_RESULT",
// flowType: "PRODUCT_FLOW"
// },
// flow: {
// "@type": "Flow",
// "@id": "a9007f10-7e39-4d50-8f4a-d6d03ce3d673",
// name: "natural gas, high pressure",
The final demand
In openLCA, a product system is calculated for a single demand value for a technosphere flow: a product output or waste input of the system. It is the quantitative reference of the system. In the general case, a system can have multiple demand values organized in a final demand vector \(f\) which is indexed in the same way as the technology matrix (Note that an multi-demand system can be transformed into a single demand system by simply adding an additional process column to the the technology matrix). In the result calculation, the technosphere matrix \(A\) is scaled by a scaling vector \(s\) to fulfill the final demand.
$$ f = \sum_j{A[:, j] * s_j} = A * s $$
| REST | GET result/{result-id}/demand |
| IPC | result/demand |
| Python IPC | Result.get_demand |
| Return type | TechFlowValue |
JSON-RPC via Fetch API
The example below shows the usage of this method using the JSON-RPC protocol via the Fetch API which is available in modern web-browsers or platforms like Deno.
let resp = await fetch("http://localhost:8080", {
method: "POST",
body: JSON.stringify({
jsonrpc: "2.0",
id: 1,
method: "result/demand",
params: {
"@id": "841c7110-4106-49d3-8447-38acc0805ca5",
}
})
});
let v = await resp.json();
console.log(v);
// {
// jsonrpc: "2.0",
// id: 1,
// result: {
// amount: 1,
// techFlow: {
// provider: {
// "@type": "Process",
// "@id": "4446fcf6-7b87-4eb6-9529-775f3fe0c016",
// ...
Total requirements
This method returns the total requirements of technosphere flows that are needed to fulfill the demand of the calculated product system. Mathematically, this is the diagonal of the technosphere matrix \(A\) scaled by the scaling \(s\):
$$ t = diag(s) * diag(A) $$
| REST | GET result/{result-id}/total-requirements |
| IPC | result/total-requirements |
| Python IPC | Result.get_total_requirements |
| Return type | List[TechFlowValue] |
It is also possible to get just the total requirements value of a single technosphere flow \(j\):
$$ t_j = s_j * A[j, j] $$
| REST | GET result/{result-id}/total-requirements-of/{tech-flow} |
| IPC | result/total-requirements-of |
| Python IPC | Result.get_total_requirements_of |
| Return type | TechFlowValue |
| Parameter type | TechFlow |
Examples
JSON-RPC via Fetch API
The example below shows the usage of this method using the JSON-RPC protocol via the Fetch API which is available in modern web-browsers or platforms like Deno.
let resp = await fetch("http://localhost:8080", {
method: "POST",
body: JSON.stringify({
jsonrpc: "2.0",
id: 1,
method: "result/total-requirements",
params: {
"@id": "fa78990c-3f88-455a-9f8f-bd9e536bac28",
}
})
});
let v = await resp.json();
console.log(v);
// {
// jsonrpc: "2.0",
// result: [
// { techFlow: { provider: [Object], flow: [Object] }, amount: 1 },
// { techFlow: { provider: [Object], flow: [Object] }, amount: 1 },
// { techFlow: {
// provider: [Object],
// flow: [Object] },
// amount: 15.151515151515152 }, ..
})();
Direct requirements
The direct requirements of a process \(j\) are the scaled inputs and outputs of the linked product and waste flows of that process related to the final demand of the product system. Mathematically, it is the scaled column \(j\) of the technology matrix \(A\):
$$ s_j * A[:,j] $$
The returned values are negative for inputs and positive for outputs of the respective flows. Also, the returned values contain the total requirements of the technosphere flow \(j\) to which the other requirements are related.
| REST | GET result/{result-id}/direct-requirements-of/{tech-flow} |
| IPC | result/direct-requirements-of |
| Python IPC | Result.get_direct_requirements_of |
| Return type | List[TechFlowValue] |
| Parameter type | TechFlow |
Examples
JSON-RPC via Fetch API
The example below shows the usage of this method using the JSON-RPC protocol via the Fetch API which is available in modern web-browsers or platforms like Deno.
let resp = await fetch("http://localhost:8080", {
method: "POST",
body: JSON.stringify({
jsonrpc: "2.0",
id: 1,
method: "result/direct-requirements-of",
params: {
"@id": "77ccaffa-9d79-4f38-8da5-4413469b8a7b",
techFlow: {
provider: {
"@type": "Process",
"@id": "ff6b1c80-03b2-4433-adaf-66c51063b078",
},
flow: {
"@type": "Flow",
"@id": "759b89bd-3aa6-42ad-b767-5bb9ef5d331d",
}
}
}
})
});
let v = await resp.json();
console.log(v);
// {
// jsonrpc: "2.0",
// result: [
// {
// techFlow: { provider: [Object], flow: [Object] },
// amount: 0.0029162004774116275
// },
// { techFlow: ...
})();
Scaling factors
The scaling vector \(s\) contains for each process \(j\) a factor \(s_j\) by which the process needs to be scaled to fulfill the demand of the product system. Mathematically, it can be calculating by solving the following equation by \(s\) where \(A\) is the technology matrix and \(f\) the final demand vector of the system:
$$ A * s = f $$
| REST | GET result/{result-id}/scaling-factors |
| IPC | result/scaling-factors |
| Python IPC | Result.get_scaling_factors |
| Return type | List[TechFlowValue] |
Examples
JSON-RPC via Fetch API
The example below shows the usage of this method using the JSON-RPC protocol via the Fetch API which is available in modern web-browsers or platforms like Deno.
let resp = await fetch("http://localhost:8080", {
method: "POST",
body: JSON.stringify({
jsonrpc: "2.0",
id: 1,
method: "result/scaling-factors",
params: {
"@id": "fa78990c-3f88-455a-9f8f-bd9e536bac28",
}
})
});
let v = await resp.json();
console.log(v);
// {
// jsonrpc: "2.0",
// result: [
// {
// techFlow: { provider: [Object], flow: [Object] },
// amount: 0.0016129032258064518
// },
// { techFlow: ...
})();
Totality factors
The concept of totality factors is a bit complicated, but they are very useful for visualizations like Sankey diagrams. In short, they scale an intensity result to a total result. An intensity result is related to one unit of product output (waste input) of a technosphere flow \(j\) including the direct, upstream, and downstream contributions. Multiplying such an intensity with the totality factor \(tf_j\) gives the total result related to the total requirements of product (waste) \(j\). Directly multiplying the intensity with the total requirements would double count possible loops.
Mathematically, the totality factor of a technosphere flow \(j\) is calculated by multiplying the total requirements \(t_j\) of that flow by a loop factor \(\lambda_j\):
$$ tf_j = \lambda_j * t_j $$
Where the loop factor is calculated via:
$$ \lambda_j = \frac{1}{A[j, j] * A^{-1}[j, j]} $$
| REST | GET result/{result-id}/totality-factors |
| IPC | result/totality-factors |
| Python IPC | Result.get_totality_factors |
| Return type | List[TechFlowValue] |
As the calculation of a totality factor \(tf_j\) requires to solve the complete system for one unit of techosphere flow \(j\), it is almost always a better idea to only query the API for totality factors that are really needed:
| REST | GET result/{result-id}/totality-factor-of/{tech-flow} |
| IPC | result/totality-factor-of |
| Python IPC | Result.get_totality_factor_of |
| Return type | TechFlowValue |
| Parameter type | TechFlow |
Unscaled requirements
The unscaled requirements of a process \(j\) are the direct requirements of the process related to the quantitative reference of that process without applying a scaling factor. Mathematically, it is just the column \(j\) of the technosphere matrix \(A\):
$$ A[:, j] $$
| REST | GET result/{result-id}/unscaled-requirements-of/{tech-flow} |
| IPC | result/unscaled-requirements-of |
| Python IPC | Result.get_unscaled_requirements_of |
| Return type | List[TechFlowValue] |
| Parameter type | TechFlow |
Examples
JSON-RPC via Fetch API
The example below shows the usage of this method using the JSON-RPC protocol via the Fetch API which is available in modern web-browsers or platforms like Deno.
let resp = await fetch("http://localhost:8080", {
method: "POST",
body: JSON.stringify({
jsonrpc: "2.0",
id: 1,
method: "result/unscaled-requirements-of",
params: {
"@id": "66dcc7d0-ce47-46bf-b77a-ada4b4c95169",
"techFlow": {
provider: {
"@type": "Process",
"@id": "ff6b1c80-03b2-4433-adaf-66c51063b078",
},
flow: {
"@type": "Flow",
"@id": "759b89bd-3aa6-42ad-b767-5bb9ef5d331d",
}
}
}
})
});
let v = await resp.json();
console.log(v);
// {
// jsonrpc: "2.0",
// result: [
// { techFlow: { provider: [Object], flow: [Object] }, amount: 3.6 },
// { techFlow: { ...
Intervention flows
This method returns the \(m\) intervention flows of a result. These are
the flows that cross the boundary with the environment of the calculated
system (this is why the short name is EnviFlow in the API). In regionalized
calculations these flows can be pairs of flows and locations, the same flow
can occur in different locations (with possibly different characterisation
factors). The rows of the intervention matrix are indexed by these \(m\)
intervention flows (and the columns by the \(n\) technosphere flows):
$$ B \in \mathbb{R}^{m \times n} $$
| REST | result/{result-id}/envi-flows |
| IPC | result/envi-flows |
| Python IPC | Result.get_envi_flows |
| Return type | List[EnviFlow] |
Examples
Python IPC
envi_flows = result.get_envi_flows()
print(
pd.DataFrame(
[
(ef.is_input, ef.flow.name, ef.flow.category, ef.flow.ref_unit)
for ef in envi_flows
],
columns=["Is input?", "Flow", "Category", "Unit"],
).head()
)
# Is input? Flow Category Unit
# 0 False 1,4-dioxane Elementary Flows/air/unspecified kg
# 1 False oryzalin Elementary Flows/soil/groundwater kg
# 2 False Sethoxydim Elementary Flows/soil/groundwater kg
# 3 False Chlorpyrifos Elementary Flows/air/low population density kg
# 4 False lead Elementary Flows/air/unspecified kg
JSON-RPC via Fetch API
The example below shows the usage of this method using the JSON-RPC protocol via the Fetch API which is available in modern web-browsers or platforms like Deno.
let resp = await fetch("http://localhost:8080", {
method: "POST",
body: JSON.stringify({
jsonrpc: "2.0",
id: 1,
method: "result/envi-flows",
params: {
"@id": "66dcc7d0-ce47-46bf-b77a-ada4b4c95169",
}
})
});
let v = await resp.json();
console.log(v);
// {
// jsonrpc: "2.0",
// result: [
// {
// flow: {
// "@type": "Flow",
// "@id": "60ea7a31-8f27-46af-bfe5-66417f00088b",
// name: "Barite",
// category: "Elementary flows/Emission to water/ocean",
// flowType: "ELEMENTARY_FLOW",
// refUnit: "kg"
// },
// isInput: false
// },
// {
// flow: {
// "@type": "Flow",
Inventory result
This method returns the inventory result \(g\) of the calculated product system. This is the amount \(g_i\) of each intervention flow \(i\) that crosses the boundary to the environment related to the final demand of product system. It can be calculated by multiplying the intervention matrix \(B\) with the scaling vector \(s\):
$$ g = B * s $$
| REST | GET result/{result-id}/total-flows |
| IPC | result/total-flows |
| Python IPC | Result.get_total_flows |
| Return type | List[EnviFlowValue] |
It is also possible to get the inventory result \(g_i\) of a single flow \(i\):
| REST | GET result/{result-id}/total-flow-value-of/{envi-flow} |
| IPC | result/total-flow-value-of |
| Python IPC | Result.get_total_flow_value_of |
| Return type | EnviFlowValue |
| Parameter type | EnviFlow |
Examples
JSON-RPC via Fetch API
The example below shows the usage of this method using the JSON-RPC protocol via the Fetch API which is available in modern web-browsers or platforms like Deno.
let resp = await fetch("http://localhost:8080", {
method: "POST",
body: JSON.stringify({
jsonrpc: "2.0",
id: 1,
method: "result/total-flows",
params: {
"@id": "66dcc7d0-ce47-46bf-b77a-ada4b4c95169",
}
})
});
let v = await resp.json();
console.log(v);
// {
// jsonrpc: "2.0",
// result: [
// { enviFlow: { flow: [Object], isInput: false }, amount: 5.316452367058923e-12 },
// { enviFlow: { flow: [Object], isInput: false }, amount: 0.0000020503441278781976 },
// { enviFlow: { flow: [Object], isInput: false }, amount: 2.2757672132330865e-10 },
// { enviFlow: { flow: [Object], isInput: false }, amount: 5.003477809709274e-7 },
// { enviFlow: { flow: [Object], isInput: true }, amount: 0.0013196599415652454 },
Direct contributions
This method returns the direct contribution of each process \(j\) in the system to the inventory result of a flow \(i\). Mathematically, it is the row \(G[i, :]\) of the scaled intervention matrix \(G\):
$$ G = B * diag(s) $$
| REST | GET result/{result-id}/direct-flow-values-of/{envi-flow} |
| IPC | result/direct-flow-values-of |
| Python IPC | Result.get_direct_flow_values_of |
| Return type | List[TechFlowValue] |
| Parameter type | EnviFlow |
Examples
JSON-RPC via Fetch API
The example below shows the usage of this method using the JSON-RPC protocol via the Fetch API which is available in modern web-browsers or platforms like Deno.
let resp = await fetch("http://localhost:8080", {
method: "POST",
body: JSON.stringify({
jsonrpc: "2.0",
id: 1,
method: "result/direct-flow-values-of",
params: {
"@id": "66dcc7d0-ce47-46bf-b77a-ada4b4c95169",
enviFlow: {
flow: {
"@type": "Flow",
"@id": "5f7aad3d-566c-4d0d-ad59-e765f971aa0f",
name: "Methane, fossil",
},
}
}
})
});
let v = await resp.json();
console.log(v);
// {
// jsonrpc: "2.0",
// result: [
// {
// techFlow: { provider: [Object], flow: [Object] },
// amount: 1.5185665316633185e-8
// },
// {
// techFlow: { provider: [Object], flow: [Object] },
// amount: 0.0018045126002407595
// }, ...
Total values
This method returns for each process \(j\) in the product system the total inventory result for a flow \(j\) at this point in the supply chain including the direct, upstream, and downstream (related to waste treatment) contributions. Mathematically, this is the row \(i\) of the intensity matrix \(M\) scaled by the totality factors \(tf\):
$$ M[i,:] * diag(tf) $$
| REST | GET result/{result-id}/total-flow-values-of/{envi-flow} |
| IPC | result/total-flow-values-of |
| Python IPC | Result.get_total_flow_values_of |
| Return type | List[TechFlowValue] |
| Parameter type | EnviFlow |
Examples
JSON-RPC via Fetch API
The example below shows the usage of this method using the JSON-RPC protocol via the Fetch API which is available in modern web-browsers or platforms like Deno.
let resp = await fetch("http://localhost:8080", {
method: "POST",
body: JSON.stringify({
jsonrpc: "2.0",
id: 1,
method: "result/total-flow-values-of",
params: {
"@id": "66dcc7d0-ce47-46bf-b77a-ada4b4c95169",
enviFlow: {
flow: {
"@type": "Flow",
"@id": "5f7aad3d-566c-4d0d-ad59-e765f971aa0f",
name: "Methane, fossil",
},
}
}
})
});
let v = await resp.json();
console.log(v);
// {
// jsonrpc: "2.0",
// result: [
// {
// techFlow: { provider: [Object], flow: [Object] },
// amount: 0.0037571867032375776
// },
// {
// techFlow: { provider: [Object], flow: [Object] },
// amount: 0.000006654150590167164
// }, ...
Direct process results
This method returns the direct intervention flows related to the production of a product (or treatment of a waste) of a process \(j\) in order to fulfill the demand of the product system. Mathematically, it is the column \(j\) of the scaled intervention matrix \(G\):
$$ G = B * diag(s) $$
| REST | GET result/{result-id}/direct-flows-of/{tech-flow} |
| IPC | result/direct-flows-of |
| Python IPC | Result.get_direct_flows_of |
| Return type | List[EnviFlowValue] |
| Parameter type | TechFlow |
It is also possible to get the direct result of a single flow \(i\):
| REST | GET result/{result-id}/direct-flow-of/{envi-flow}/{tech-flow} |
| IPC | result/direct-flow-of |
| Python IPC | Result.get_direct_flow_of |
| Return type | EnviFlowValue |
| Parameter type | EnviFlow |
| Parameter type | TechFlow |
Examples
JSON-RPC via Fetch API
The example below shows the usage of this method using the JSON-RPC protocol via the Fetch API which is available in modern web-browsers or platforms like Deno.
let resp = await fetch("http://localhost:8080", {
method: "POST",
body: JSON.stringify({
jsonrpc: "2.0",
id: 1,
method: "result/direct-flows-of",
params: {
"@id": "66dcc7d0-ce47-46bf-b77a-ada4b4c95169",
techFlow: {
provider: {
"@type": "Process",
"@id": "ff6b1c80-03b2-4433-adaf-66c51063b078",
},
flow: {
"@type": "Flow",
"@id": "759b89bd-3aa6-42ad-b767-5bb9ef5d331d",
}
}
}
})
});
let v = await resp.json();
console.log(v);
// {
// jsonrpc: "2.0",
// result: [
// { enviFlow: { flow: [Object], isInput: false },
// amount: 2.4884640352310415e-19 },
// { enviFlow: { flow: [Object], isInput: false },
// amount: 1.0147225898077544e-12 }, ...
Total process results
This method returns the total results related to the total requirements $t_j$ of a technosphere flow \(j\)) in the calculated product system. This includes the direct, upstream, and downstream contributions related to $t_j$. Mathematically, it is the column \(j\) of the intensity matrix \(M\) scaled by the totality factor \(tf_j\):
$$ M[:,j] * tf_j $$
| REST | GET result/{result-id}/total-flows-of/{tech-flow} |
| IPC | result/total-flows-of |
| Python IPC | Result.get_total_flows_of |
| Return type | List[EnviFlowValue] |
| Parameter type | TechFlow |
It is also possible to get the total result value for a single flow:
| REST | GET result/{result-id}/total-flow-of/{envi-flow}/{tech-flow} |
| IPC | result/total-flow-of |
| Python IPC | Result.get_total_flow_of |
| Return type | EnviFlowValue |
| Parameter type | EnviFlow |
| Parameter type | TechFlow |
Intensities
This method returns the total interventions related to one unit of product output or waste input of a technosphere flow \(j\) in the supply chain. This includes direct, upstream, and downstream contributions related to one unit of this flow. Mathematically, it is the column \(M[:, j]\) of the intensity matrix \(M\):
$$ M = B * A^{-1} $$
| REST | GET result/{result-id}/total-flows-of-one/{tech-flow} |
| IPC | result/total-flows-of-one |
| Python IPC | Result.get_total_flows_of_one |
| Return type | List[EnviFlowValue] |
| Parameter type | TechFlow |
It is also possible to get the intensity result of a single flow:
| REST | GET result/{result-id}/total-flow-of-one/{envi-flow}/{tech-flow} |
| IPC | result/total-flow-of-one |
| Python IPC | Result.get_total_flow_of_one |
| Return type | EnviFlowValue |
| Parameter type | EnviFlow |
| Parameter type | TechFlow |
Unscaled flows
This method returns the unscaled direct interventions related to the quantitative reference of a process \(j\). Mathematically, this is just the column \(j\) of the intervention matrix \(B\)):
$$ B[:, j] $$
| REST | GET result/{result-id}/unscaled-flows-of/{tech-flow} |
| IPC | result/unscaled-flows-of |
| Python IPC | Result.get_unscaled_flows_of |
| Return type | List[EnviFlowValue] |
| Parameter type | TechFlow |
Upstream results
This method returns the upstream results for a given path in an upstream contribution tree related to an intervention flow. If the path is empty, the root of that tree is returned.
| REST | POST result/{result-id}/upstream-interventions-of/{envi-flow} |
| IPC | result/upstream-interventions-of |
| Python IPC | Result.get_upstream_interventions_of |
| Return type | List[UpstreamNode] |
| Parameter | EnviFlow |
| Parameter | the upstream path encoded as string |
Upstream trees
This method returns the result nodes of a given intervention flow for a given path in an upstream contribution tree. The path is a sequence of technosphere-flows that describe the path to the parent node of the returned nodes. If the path is empty, the root of the tree is returned. Note that such an upstream tree can be infinitely deep when the calculated system has cycles.
| Rest API | POST result/{result-id}/upstream-interventions-of/{envi-flow} |
| JSON-RPC | result/upstream-interventions-of |
| Snake case | result.get_upstream_interventions_of |
| Camel case | result.getUpstreamInterventionsOf |
| Return type | List[UpstreamNode] |
| Parameter 1 | EnviFlow |
| Parameter 2 | List[TechFlow] |
Examples
olca-ipc.ts
The TypeScript example below uses the olca-ipc.ts client API:
async function main() {
// connect to a local server running on port 8080
const client = o.IpcClient.on(8080);
const setup = o.CalculationSetup.of({
target: o.Ref.of({
id: "d3a9a9b2-ec3e-4811-8617-ae853573b50b",
refType: o.RefType.ProductSystem,
}),
});
const result = await client.calculate(setup);
await result.untilReady();
// select the first best inventory flow and expand a tree for it
const flow = (await result.getEnviFlows())[0];
console.log(`upstream tree for ${flow.flow?.name} (${flow.flow?.category})`);
await expand(result, flow, []);
// as always, dispose the result
result.dispose();
}
async function expand(r: o.IpcResult, flow: o.EnviFlow, path: o.TechFlow[]) {
const level = path.length;
const indent = " ".repeat(level);
const unit = flow.flow?.refUnit;
const nodes = await r.getUpstreamInterventionsOf(flow, path);
for (const node of nodes) {
if (node.result === 0) {
continue;
}
const name = node.techFlow?.provider?.name;
const value = node.result?.toExponential(2);
console.log(`${indent}- ${value} ${unit} :: ${name}`);
// we stop the expansion after 3 levels; you can set other cut-offs like
// result contributions etc.
if (level < 3) {
const next = path.slice();
next.push(node.techFlow!);
await expand(r, flow, next);
}
}
}
main();
/*
upstream tree for COD, Chemical Oxygen Demand (Elementary flows/Emission to water/ground water)
- 1.73e-9 t :: ...
- 1.73e-9 t :: ...
- 7.21e-10 t :: ...
- 3.45e-10 t :: ...
- 2.04e-10 t :: ...
- ...
- 5.77e-10 t :: ...
- 4.40e-10 t :: ...
- 7.53e-11 t :: ...
- 3.21e-11 t :: ...
- ...
*/
olca-ipc.py
The Python example below uses the olca-ipc.py client API:
import olca_ipc as ipc
import olca_schema as o
def main():
# calculate a result
client = ipc.Client(8080)
setup = o.CalculationSetup(
target=o.Ref(
id="d3a9a9b2-ec3e-4811-8617-ae853573b50b",
ref_type=o.RefType.ProductSystem,
)
)
result = client.calculate(setup)
result.wait_until_ready()
# select the first best inventory flow and expand a tree for it
flow = result.get_envi_flows()[0]
print(f"upstream tree for {flow.flow.name} ({flow.flow.category})")
expand(result, flow, [])
# as always, dispose the result
result.dispose()
def expand(r: ipc.IpcResult, flow: o.EnviFlow, path: list[o.TechFlow]):
level = len(path)
indent = " " * level
unit = flow.flow.ref_unit
nodes = r.get_upstream_interventions_of(flow, path)
for node in nodes:
if node.result == 0 or not node.tech_flow:
continue
name = node.tech_flow.provider.name
value = node.result
print(f"{indent}- {value:.2E} {unit} :: {name}")
# we stop the expansion after 3 levels; you can set other cut-offs like
# result contributions etc.
if level < 3:
expand(r, flow, path + [node.tech_flow])
pass
if __name__ == "__main__":
main()
Grouped results
Returns the analysis group results for a given flow.
| Rest API | GET result/{result-id}/grouped-flow-results-of/{envi-flow} |
| JSON-RPC | result/grouped-flow-results-of |
| Snake case | result.get_grouped_flow_results_of |
| Camel case | result.getGroupedFlowResultsOf |
| Return type | List[GroupValue] |
| Parameter 1 | EnviFlow |
Impact categories
This method returns the \(l\) impact categories of a result. The rows of the impact matrix \(C\) are indexed by these impact categories and the columns by the \(m\) intervention flows of the system. \(C\) contains the respective characterisation factors of the intervention flows.
$$ C \in \mathbb{R}^{l \times m} $$
| REST | result/{result-id}/impact-categories |
| IPC | result/impact-categories |
| Python IPC | Result.get_impact_categories |
| Return type | List[Ref[ImpactCategory]] |
Examples
Python IPC
impact_categories = result.get_impact_categories()
print(
pd.DataFrame(
[(i.name, i.ref_unit) for i in impact_categories],
columns=["Impact category", "Unit"],
)
)
# Impact category Unit
# 0 OZON kg CFC11-eq
# 1 EUTR kg N eq
# 2 SMOG kg O3 eq
# 3 HNC CTUh
# 4 ETOX CTUe
# 5 HC CTUh
# 6 HRSP kg PM2.5 eq
# 7 GCC kg CO2 eq
# 8 HTOX CTUh
# 9 ACID kg SO2-eq
JSON-RPC via Fetch API
The example below shows the usage of this method using the JSON-RPC protocol via the Fetch API which is available in modern web-browsers or platforms like Deno.
let resp = await fetch("http://localhost:8080", {
method: "POST",
body: JSON.stringify({
jsonrpc: "2.0",
id: 1,
method: "result/impact-categories",
params: {
"@id": "4780f66c-0b77-49ca-9226-c7ce4447ea2d",
}
})
});
let v = await resp.json();
console.log(v);
// {
// jsonrpc: "2.0",
// result: [
// {
// "@type": "ImpactCategory",
// "@id": "2dddb0a4-2f97-3fef-a4e6-708f0b4c2554",
// name: "Human toxicity, cancer - inorganics",
// category: "EF 3.0 Method (adapted)",
// refUnit: "CTUh"
// },
// {
// "@type": "ImpactCategory",
// "@id": "248a3f3f-933e-3c45-a799-fad9f956e03c",
// name: "Photochemical ozone formation",
// category: "EF 3.0 Method (adapted)",
// refUnit: "kg NMVOC eq"
// },
Impact assessment result
This method returns the impact assessment result of the calculated product system. It can be calculated by multiplying the characterisation matrix \(C\) with the inventory result \(g\):
$$ h = C * g $$
| REST | GET result/{result-id}/total-impacts |
| IPC | result/total-impacts |
| Python IPC | Result.get_total_impacts |
| Return type | List[ImpactValue] |
It is also possible to get the impact result \(h_k\) for a single impact category \(k\):
| REST | GET result/{result-id}/total-impact-value-of/{impact-category} |
| IPC | result/total-impact-value-of |
| Python IPC | Result.get_total_impact_value_of |
| Return type | ImpactValue |
| Parameter type | Ref[ImpactCategory] |
Examples
JSON-RPC via Fetch API
The example below shows the usage of this method using the JSON-RPC protocol via the Fetch API which is available in modern web-browsers or platforms like Deno.
let resp = await fetch("http://localhost:8080", {
method: "POST",
body: JSON.stringify({
jsonrpc: "2.0",
id: 1,
method: "result/total-impacts",
params: {
"@id": "86b36d3b-1dba-4804-bd61-dc5bcaf7c86c",
}
})
});
let v = await resp.json();
console.log(v);
// {
// jsonrpc: "2.0",
// result: [
// {
// impactCategory: {
// "@type": "ImpactCategory",
// "@id": "3bc1c67f-d3e3-3891-9fea-4512107d88ef",
// name: "Climate change",
// category: "EF 3.0 Method (adapted)",
// refUnit: "kg CO2 eq"
// },
// amount: 0.6387478227404646
// },
// ...
Normalized results
This method returns the normalized impact assessment result of the calculated product system. Mathematically, it is the impact assessment result \(h\) devided by the respective normalization values \(nv\):
$$ diag(nv)^{-1} * h $$
| REST | GET result/{result-id}/total-impacts/normalized |
| IPC | result/total-impacts/normalized |
| Python IPC | Result.get_total_impacts_normalized |
| Return type | List[ImpactValue] |
Examples
JSON-RPC via Fetch API
The example below shows the usage of this method using the JSON-RPC protocol via the Fetch API which is available in modern web-browsers or platforms like Deno.
let resp = await fetch("http://localhost:8080", {
method: "POST",
body: JSON.stringify({
jsonrpc: "2.0",
id: 1,
method: "result/total-impacts/normalized",
params: {
"@id": "15432ac4-7752-4066-a62d-31270f6a0dbd",
}
})
});
let v = await resp.json();
console.log(v);
//{
// jsonrpc: "2.0",
// result: [
// {
// impactCategory: {
// "@type": "ImpactCategory",
// "@id": "248a3f3f-933e-3c45-a799-fad9f956e03c",
// name: "Photochemical ozone formation",
// category: "EF 3.0 Method (adapted)",
// refUnit: "kg NMVOC eq"
// },
// amount: 0.0010466725460636012
// },
olca-ipc.py
The example below shows how to get normalized impact assessment results using olca-ipc.py:
import olca_ipc as ipc
import olca_schema as o
client = ipc.Client()
# get the impact assessment method
method = client.get(o.ImpactMethod, "bf665139-3159-45ef-9b00-f439251d2b5b")
# select the first normalisation & weighting set for the example;
# make sure the method has nw-sets
nwset = method.nw_sets[0]
# run a calculation
result = client.calculate(o.CalculationSetup(
target=o.Ref(
id="7d1cbce0-b5b3-47ba-95b5-014ab3c7f569",
ref_type=o.RefType.ProductSystem,
),
impact_method=method.to_ref(),
nw_set=nwset.to_ref(),
))
result.wait_until_ready()
# print the normalized results
for nr in result.get_normalized_impacts():
print(f"{nr.impact_category.name} :: {nr.amount}")
result.dispose()
Weighted results
This method returns the weighted impact assessment result of the calculated product system. Mathematically, it is the impact assessment result \(h\) devided by the respective normalization values \(nv\) and multiplied with the respective weighting factors \(w\):
$$ diag(w) * diag(nv)^{-1} * h $$
| REST | GET result/{result-id}/total-impacts/weighted |
| IPC | result/total-impacts/weighted |
| Python IPC | Result.get_total_impacts_weighted |
| Return type | List[ImpactValue] |
Examples
JSON-RPC via Fetch API
The example below shows the usage of this method using the JSON-RPC protocol via the Fetch API which is available in modern web-browsers or platforms like Deno.
let resp = await fetch("http://localhost:8080", {
method: "POST",
body: JSON.stringify({
jsonrpc: "2.0",
id: 1,
method: "result/total-impacts/weighted",
params: {
"@id": "546a1d13-3cae-4c9b-82d0-a18204b0c6eb",
}
})
});
let v = await resp.json();
console.log(v);
//{
// jsonrpc: "2.0",
// result: [
// {
// {
// impactCategory: {
// "@type": "ImpactCategory",
// "@id": "3bc1c67f-d3e3-3891-9fea-4512107d88ef",
// name: "Climate change",
// category: "EF 3.0 Method (adapted)",
// refUnit: "kg CO2 eq"
// },
// amount: 2.038186234380937
// },
// },
olca-ipc.py
The example below shows how to get weighted impact assessment results using olca-ipc.py:
import olca_ipc as ipc
import olca_schema as o
client = ipc.Client()
# get the impact assessment method
method = client.get(o.ImpactMethod, "bf665139-3159-45ef-9b00-f439251d2b5b")
# select the first normalisation & weighting set for the example;
# make sure the method has nw-sets
nwset = method.nw_sets[0]
# run a calculation
result = client.calculate(o.CalculationSetup(
target=o.Ref(
id="7d1cbce0-b5b3-47ba-95b5-014ab3c7f569",
ref_type=o.RefType.ProductSystem,
),
impact_method=method.to_ref(),
nw_set=nwset.to_ref(),
))
result.wait_until_ready()
# print the weighted results
for wr in result.get_weighted_impacts():
print(f"{wr.impact_category.name} :: {wr.amount} {nwset.weighted_score_unit}")
result.dispose()
Direct contributions
This method returns the direct contribution of each process \(j\) in the system to the impact assessment result of an impact category \(k\). Mathematically, this is the row \(H[k, :]\) of the direct impact matrix which can be calculated in the following way:
$$ H = C * B * diag(s) $$
| REST | GET result/{result-id}/direct-impact-values-of/{impact-category} |
| IPC | result/direct-impact-values-of |
| Python IPC | Result.get_direct_impact_values_of |
| Return type | List[TechFlowValue] |
| Parameter type | Ref[ImpactCategory] |
Examples
JSON-RPC via Fetch API
The example below shows the usage of this method using the JSON-RPC protocol via the Fetch API which is available in modern web-browsers or platforms like Deno.
let resp = await fetch("http://localhost:8080", {
method: "POST",
body: JSON.stringify({
jsonrpc: "2.0",
id: 1,
method: "result/direct-impact-values-of",
params: {
"@id": "86b36d3b-1dba-4804-bd61-dc5bcaf7c86c",
impactCategory: {
"@id": "dbdd01d5-2be4-3ba4-8127-de89f065fda1",
},
}
})
});
let v = await resp.json();
console.log(v);
// {
// jsonrpc: "2.0",
// result: [
// {
// techFlow: { provider: [Object], flow: [Object] },
// amount: 0.00008582892489209728
// },
// { techFlow: { provider: [Object], flow: [Object] },
// amount: 2.023594297933216 },
// ...
Direct process result
This method returns the direct impacts of a process \(j\) in the calculated product system. Mathematically, it is the column \(H[:, j]\) of the direct impact matrix:
$$ H = C * B * diag(s) $$
| REST | GET result/{result-id}/direct-impacts-of/{tech-flow} |
| IPC | result/direct-impacts-of |
| Python IPC | Result.get_direct_impacts_of |
| Return type | List[ImpactValue] |
| Parameter type | TechFlow |
It is also possible to get the direct process result \(H[k, j]\) for a single impact category \(k\):
| REST | GET result/{result-id}/direct-impact-of/{impact-category}/{tech-flow} |
| IPC | result/direct-impact-of |
| Python IPC | Result.get_direct_impact_of |
| Return type | ImpactValue |
| Parameter type | Ref[ImpactCategory] |
| Parameter type | TechFlow |
Examples
JSON-RPC via Fetch API
The example below shows the usage of this method using the JSON-RPC protocol via the Fetch API which is available in modern web-browsers or platforms like Deno.
let resp = await fetch("http://localhost:8080", {
method: "POST",
body: JSON.stringify({
jsonrpc: "2.0",
id: 1,
method: "result/direct-impacts-of",
params: {
"@id": "86b36d3b-1dba-4804-bd61-dc5bcaf7c86c",
techFlow: {
provider: { "@id": "37eb4bf5-9fbc-4caf-a24a-0e0b71b997dd" },
flow: { "@id": "817c3650-4fed-4ef2-b9b6-404a198834e6" }
}
}
})
});
let v = await resp.json();
console.log(v);
// {
// jsonrpc: "2.0",
// result: [
// {
// impactCategory: {
// "@type": "ImpactCategory",
// "@id": "3bc1c67f-d3e3-3891-9fea-4512107d88ef",
// name: "Climate change",
// category: "EF 3.0 Method (adapted)",
// refUnit: "kg CO2 eq"
// },
// amount: 0.0008854099635082675
// },
// ...
Total process result
This method returns the total impact result related to the total requirements \(t_j\) of a technosphere flow \(j\) in the calculated product system. This includes the direct, upstream, and downstream contributions related to $t_j$. Mathematically, it is the column \(j\) of the impact intensity matrix \(N\) scaled by the totality factor \(tf_j\):
$$ M[:,j] * tf_j $$
| REST | GET result/{result-id}/total-impacts-of/{tech-flow} |
| IPC | result/total-impacts-of |
| Python IPC | Result.get_total_impacts_of |
| Return type | List[ImpactValue] |
| Parameter type | TechFlow |
It is also possible to get the total impact result for a single impact category:
| REST | GET result/{result-id}/total-impact-of/{impact-category}/{tech-flow} |
| IPC | result/total-impact-of |
| Python IPC | Result.get_total_impact_of |
| Return type | ImpactValue |
| Parameter type | Ref[ImpactCategory] |
| Parameter type | TechFlow |
Examples
JSON-RPC via Fetch API
The example below shows the usage of this method using the JSON-RPC protocol via the Fetch API which is available in modern web-browsers or platforms like Deno.
let resp = await fetch("http://localhost:8080", {
method: "POST",
body: JSON.stringify({
jsonrpc: "2.0",
id: 1,
method: "result/total-impacts-of",
params: {
"@id": "86b36d3b-1dba-4804-bd61-dc5bcaf7c86c",
techFlow: {
provider: { "@id": "37eb4bf5-9fbc-4caf-a24a-0e0b71b997dd" },
flow: { "@id": "817c3650-4fed-4ef2-b9b6-404a198834e6" }
}
}
})
});
let v = await resp.json();
console.log(v);
// {
// jsonrpc: "2.0",
// result: [
// {
// impactCategory: {
// "@type": "ImpactCategory",
// "@id": "3bc1c67f-d3e3-3891-9fea-4512107d88ef",
// name: "Climate change",
// category: "EF 3.0 Method (adapted)",
// refUnit: "kg CO2 eq"
// },
// amount: 0.020981112466506135
// },
// ...
Intensities
This method returns the total impacts related to one unit of product output or waste input of a technosphere flow \(j\) in the supply chain. This includes direct, upstream, and downstream contributions related to one unit of this flow. Mathematically, it is the column \(N[:, j]\) of the impact intensity matrix \(N\):
$$ N = C * B * A^{-1} = C * M $$
| REST | GET result/{result-id}/total-impacts-of-one/{tech-flow} |
| IPC | result/total-impacts-of-one |
| Python IPC | Result.get_total_impacts_of_one |
| Return type | List[ImpactValue] |
| Parameter type | TechFlow |
It is also possible to get the intensity \(N[k, j]\) of a single impact category \(k\):
| REST | GET result/{result-id}/total-impact-of-one/{impact-category}/{tech-flow} |
| IPC | result/total-impact-of-one |
| Python IPC | Result.get_total_impact_of_one |
| Return type | ImpactValue |
| Parameter type | Ref[ImpactCategory] |
| Parameter type | TechFlow |
Examples
JSON-RPC via Fetch API
The example below shows the usage of this method using the JSON-RPC protocol via the Fetch API which is available in modern web-browsers or platforms like Deno.
let resp = await fetch("http://localhost:8080", {
method: "POST",
body: JSON.stringify({
jsonrpc: "2.0",
id: 1,
method: "result/total-impacts-of-one",
params: {
"@id": "86b36d3b-1dba-4804-bd61-dc5bcaf7c86c",
techFlow: {
provider: { "@id": "37eb4bf5-9fbc-4caf-a24a-0e0b71b997dd" },
flow: { "@id": "817c3650-4fed-4ef2-b9b6-404a198834e6" }
}
}
})
});
let v = await resp.json();
console.log(v);
// {
// jsonrpc: "2.0",
// result: [
// {
// impactCategory: {
// "@type": "ImpactCategory",
// "@id": "3bc1c67f-d3e3-3891-9fea-4512107d88ef",
// name: "Climate change",
// category: "EF 3.0 Method (adapted)",
// refUnit: "kg CO2 eq"
// },
// amount: 1.3687522905554603
// },
// ...
Upstream results
This method returns the upstream results for a given path in an upstream contribution tree related to an impact category. If the path is empty, the root of that tree is returned.
| REST | POST result/{result-id}/upstream-impacts-of/{impact-category} |
| IPC | result/upstream-impacts-of |
| Python IPC | Result.get_upstream_impacts_of |
| Return type | List[UpstreamNode] |
| Parameter | Ref[ImpactCategory] |
| Parameter | the upstream path encoded as string |
Upstream trees
This method returns the result nodes of a given impact category for a given path in an upstream contribution tree. The path is a sequence of technosphere-flows that describe the path to the parent node of the returned nodes. If the path is empty, the root of the tree is returned. Note that such an upstream tree can be infinitely deep when the calculated system has cycles.
| Rest API | POST result/{result-id}/upstream-impacts-of/{impact-category} |
| JSON-RPC | result/upstream-impacts-of |
| Snake case | result.get_upstream_impacts_of |
| Camel case | result.getUpstreamImpactsOf |
| Return type | List[UpstreamNode] |
| Parameter 1 | Ref[ImpactCategory] |
| Parameter 2 | List[TechFlow] |
Examples
olca-ipc.ts
The TypeScript example below uses the olca-ipc.ts client API:
async function main() {
// connect to a local server running on port 8080
const client = o.IpcClient.on(8080);
const setup = o.CalculationSetup.of({
target: o.Ref.of({
id: "d3a9a9b2-ec3e-4811-8617-ae853573b50b",
refType: o.RefType.ProductSystem,
}),
impactMethod: o.Ref.of({
id: "07370e48-dde9-4248-9a9b-7255f701da89",
})
});
const result = await client.calculate(setup);
await result.untilReady();
// select the first best impact category and expand a tree for it
const indicator = (await result.getImpactCategories())[0];
console.log(`upstream tree for ${indicator.name}`);
await expand(result, indicator, []);
// as always, dispose the result
result.dispose();
}
async function expand(r: o.IpcResult, indicator: o.Ref, path: o.TechFlow[]) {
const level = path.length;
const indent = " ".repeat(level);
const unit = indicator.refUnit;
const nodes = await r.getUpstreamImpactsOf(indicator, path);
for (const node of nodes) {
if (node.result === 0) {
continue;
}
const name = node.techFlow?.provider?.name;
const value = node.result?.toExponential(2);
console.log(`${indent}- ${value} ${unit} :: ${name}`);
// we stop the expansion after 3 levels; you can set other cut-offs like
// result contributions etc.
if (level < 3) {
const next = path.slice();
next.push(node.techFlow!);
await expand(r, indicator, next);
}
}
}
main();
/*
upstream tree for Photochemical ozone formation
- 2.66e-2 kg NMVOC eq ...
- 2.66e-2 kg NMVOC eq ...
- 1.13e-2 kg NMVOC eq ...
- 4.69e-3 kg NMVOC eq ...
- 4.53e-3 kg NMVOC eq ...
- 1.41e-3 kg NMVOC eq ...
- 8.72e-3 kg NMVOC eq ...
- 4.18e-3 kg NMVOC eq ...
- 4.18e-3 kg NMVOC eq ...
- 1.01e-4 kg NMVOC eq ...
*/
olca-ipc.py
The Python example below uses the utree module of the olca-ipc.py API which
makes working with upstream trees a bit more convenient:
import olca_schema as o
import olca_ipc as ipc
import olca_ipc.utree as utree
# maximum number of levels and child nodes that should be expanded
MAX_EXPAND_LEVELS = 3
MAX_EXPAND_NODES = 5
def main():
# calculate a result
client = ipc.Client()
setup = o.CalculationSetup(
target=o.Ref(
ref_type=o.RefType.Process,
id="2d1b0c1f-dd8f-3aea-bc50-bbd10acbd86d",
),
impact_method=o.Ref(id="99b9d86b-ec6f-4610-ba9f-68ebfe5691dd"),
)
result = client.calculate(setup)
result.wait_until_ready()
# select the first impact category for the tree
ref = result.get_impact_categories()[0]
print(f"\nTree for {ref.name}, results in {ref.ref_unit}:")
# create the upstream tree and expand it
root = utree.of(result, ref)
expand(root, 0)
# always dispose the result
result.dispose()
def expand(node: utree.Node, level: int):
"""This function recursively expands an upstream tree.
The maximum number of levels and maximum number of child nodes are defined
with the constants above. Note that an upstream tree can be
"""
indent = " " * level
print(f"{indent} - {node.provider.name} : {node.result}")
if level < MAX_EXPAND_LEVELS:
for c in node.childs[0:MAX_EXPAND_NODES]:
expand(c, level + 1)
if __name__ == "__main__":
main()
Grouped results
Returns the analysis group results for a given impact category.
| Rest API | GET result/{result-id}/grouped-impact-results-of/{impact-category} |
| JSON-RPC | result/grouped-impact-results-of |
| Snake case | result.get_grouped_impact_results_of |
| Camel case | result.getGroupedImpactResultsOf |
| Return type | List[GroupValue] |
| Parameter 1 | Ref[ImpactCategory] |
The currency of cost results
This method returns the currency of cost results if available. This is typically the reference currency of the underlying database.
| REST | GET result/{result-id}/currency |
| IPC | result/currency |
| Python IPC | Result.get_currency |
| Return type | Ref[Currency] |
Examples
Python IPC
JSON-RPC via Fetch API
The example below shows the usage of this method using the JSON-RPC protocol via the Fetch API which is available in modern web-browsers or platforms like Deno.
let resp = await fetch("http://localhost:8080", {
method: "POST",
body: JSON.stringify({
jsonrpc: "2.0",
id: 1,
method: "result/currency",
params: {
"@id": "66dcc7d0-ce47-46bf-b77a-ada4b4c95169",
}
})
});
let v = await resp.json();
console.log(v);
Life cycle costing result
This method retursn the total life cycle costing (LCC) result.
$$ q^T * s $$
| Rest API | GET result/{result-id}/total-costs |
| JSON-RPC | result/total-costs |
| Snake case | result.get_total_costs |
| Camel case | result.getTotalCosts |
| Return type | CostValue |
Examples
TypeScript IPC
const totals = await result.getTotalCosts();
const code = totals.currency?.refUnit;
console.log(`total costs: ${totals.amount} ${code}`);
// total costs: 60 USD
Direct contributions
This method returns the direct contribution of each process in the system to the total cost result.
$$ q^T * diagm(s) $$
| Rest API | GET result/{result-id}/cost-contributions |
| JSON-RPC | result/cost-contributions |
| Snake case | result.get_cost_contributions |
| Camel case | result.getCostContributions |
| Return type | List[TechFlowValue] |
Examples
TypeScript IPC
const contributions = await result.getCostContributions();
for (const c of contributions) {
console.log(`${c.techFlow?.provider?.name}: ${c.amount} ${code}`);
}
// Q: 15 USD
// P: 45 USD
Total cost values
$$ q^T * A^{-1}[:,j] * tf[j] $$
Rest: /total-costs-of/{tech-flow}
Rest: /total-cost-values
$$ q^T * A^{-1} * diagm(tf) $$
Intensities
$$ q^T * A^{-1}[:,j] $$
Rest: /total-costs-of-one/{tech-flow}
Unscaled costs
$$ q^T $$
Rest: /unscaled-costs
Upstream results
This method returns the upstream cost results for a given path in an upstream contribution tree. If the path is empty, the root of that tree is returned.
| REST | POST result/{result-id}/upstream-costs-of |
| IPC | result/upstream-costs-of |
| Python IPC | Result.get_upstream_costs_of |
| Return type | List[UpstreamNode] |
| Parameter | the upstream path encoded as string |
Upstream trees
Grouped results
Returns the analysis group results for the calculated LCC results.
| Rest API | GET result/{result-id}/grouped-cost-results |
| JSON-RPC | result/grouped-cost-results |
| Snake case | result.get_grouped_cost_results |
| Camel case | result.getGroupedCostResults |
| Return type | List[GroupValue] |
Sankey Graphs
This method returns a graph data structure with which Sankey diagrams can be constructed.
| REST | POST result/{result-id}/sankey |
| IPC | result/sankey |
| Python IPC | Result.get_sankey_graph |
| Parameter type | SankeyRequest |
| Return type | SankeyGraph |
Examples
Python IPC
import olca_ipc.rest as ipc
import olca_schema as o
# in this example we use the REST client
client = ipc.RestClient("http://localhost:8080")
# calculate a result for the default quantitative reference of a product system
result = client.calculate(
o.CalculationSetup(
target=o.Ref(
ref_type=o.RefType.ProductSystem,
id="7d1cbce0-b5b3-47ba-95b5-014ab3c7f569",
),
impact_method=o.Ref(id="99b9d86b-ec6f-4610-ba9f-68ebfe5691dd"),
)
)
result.wait_until_ready()
# get the Sankey graph for an impact category
g = result.get_sankey_graph(
o.SankeyRequest(
impact_category=o.Ref(id="b8658d7c-9c6e-4361-acbf-3bd6d9fef8c9"),
max_nodes=10,
)
)
print(f"loaded a graph with {len(g.nodes)} nodes and {len(g.edges)} edges")
# prints something like: loaded a graph with 10 nodes and 14 edges
# finally, dispose the result
result.dispose()
TypeScript IPC
// we use it as Deno module here; but it is the same for npm and friends
// with Deno, run it like this: deno run --allow-net sankey.ts
import * as o from "https://raw.githubusercontent.com/GreenDelta/olca-ipc.ts/main/mod.ts";
async function main() {
const client = o.RestClient.on("http://localhost:8080");
// calculate the result
const result = await client.calculate(o.CalculationSetup.of({
target: o.Ref.of({
refType: o.RefType.ProductSystem,
id: "7d1cbce0-b5b3-47ba-95b5-014ab3c7f569",
}),
impactMethod: o.Ref.of({ id: "99b9d86b-ec6f-4610-ba9f-68ebfe5691dd" }),
}));
await result.untilReady();
const g = await result.getSankeyGraph(o.SankeyRequest.of({
impactCategory: o.Ref.of({ id: "b8658d7c-9c6e-4361-acbf-3bd6d9fef8c9" }),
maxNodes: 10,
}));
console.log(
`loaded a graph with ${g.nodes?.length} nodes and ${g.edges?.length} edges`,
);
result.dispose();
}
main();