Introduction
Welcome to the world of scripting in openLCA! Since openLCA is a Java-based application running on the Java Virtual Machine (JVM), it comes with a powerful tool for automation and customization: Jython. Jython is an implementation of Python 2.7 that seamlessly integrates with Java, compiling Python code into Java bytecode for execution on the JVM.
The best part? openLCA comes pre-packaged with Jython 2.7, so you are ready to start scripting right
away! Just head over to Tools → Developer Tools → Python, where you will find a built-in Python
editor. There, you can write and execute scripts to automate tasks, extend functionalities, or
simply experiment with the power of Python inside openLCA.
Let’s dive in and unlock the full potential of openLCA with Jython!
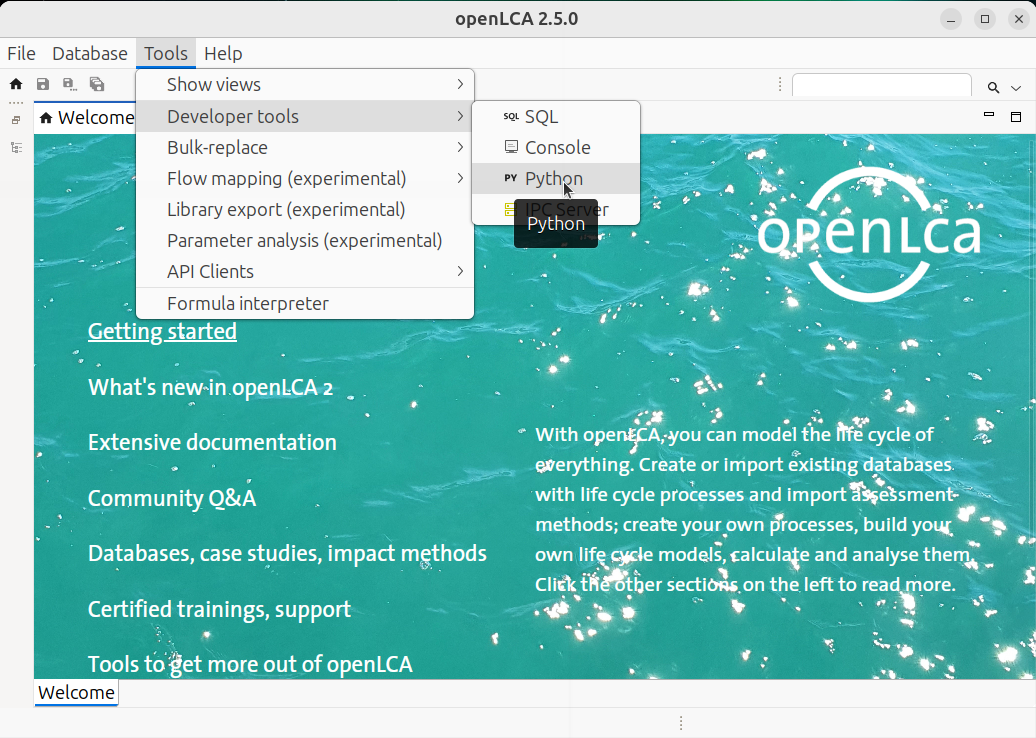
In order to execute a script, you click on the Run button in the toolbar of the Python editor:
Hello world!
As said above, you can write Python code in the Python editor and execute it. Let's start with the holy grail of coding tutorials: Hello world!
print("Hello world!")
When running this line of code, the openLCA console should appear with the message "Hello world!"
Relation to standard Python
Jython runs on the JVM. It implements a great part of the Python 2.7 standard library for the JVM. For example the following script will work when you set the file path to an existing CSV file on your system:
import csv
# Do not forget to edit this path to point to your CSV file!
FILE = "~/path/to/file.csv"
data = [
["Tea", "1.0"],
["Coffee", "2.0"],
]
with open(FILE, "w") as file:
writer = csv.writer(file)
for r in data:
writer.writerow(r)
The Jython standard library is extracted to the python folder of the openLCA workspace which is by
default located in your user directory ~/openLCA-data-1.4/python. This is also the location in
which you can put your own Jython 2.7 compatible modules. For example, when you create a file
tutorial.py with the following function in this folder:
# ~/openLCA-data-1.4/python/tutorial.py
def the_answer():
return 42
You can then load it in the openLCA script editor:
import tutorial
import org.openlca.app.util.MsgBox as MsgBox
MsgBox.info("The answer is %s!" % tutorial.the_answer())
An important thing to note is that Python modules that use C-extensions (like NumPy and friends) or parts of the standard library that are not implemented in Jython are not compatible with Jython. If you want to interact from standard CPython with openLCA (using Pandas, NumPy, etc.) you can use the openLCA IPC Python API.
The openLCA API
Earlier, we mentioned that with Jython you directly access the openLCA Java API. You interact with a
Java class in the same way as with a Python class. The openLCA API starts with a set of classes that
describe the basic data model, like Flow, Process, ProductSystem. You can find these classes
in the
olca-module repository.
More information in the The basic data model chapter.
About this manual
⚠️ NOTE: This documentation was written for and tested with openLCA 2.5.0. While many examples and techniques still work in newer versions, some functionality may have changed.
We encourage you to:
-
Open an issue if you encounter something that does not work or is unclear.
-
Contribute improvements, fixes, or new examples. If you have built a useful script or utility with Jython in openLCA, others would certainly benefit from it.
-
Share feedback, questions, or suggestions in the openLCA forum.
This manual is community-driven. Your contributions—be it fixing outdated code, adding usage tips, or documenting common pitfalls—will make this guide more helpful for everyone.
Feel free to fork the repository, suggest edits, or just open an issue describing what you'd like to add or improve.
Happy scripting! 🐍
A minimal example
This chapter provides a straightforward example of using the openLCA Jython interface to access datasets and perform a calculation.
The objective is to create a basic model for boiling water and evaluate its environmental impact using the EPD 2018 impact method. This example serves as a starting point for working with openLCA programmatically, demonstrating how to retrieve data and run calculations efficiently.
Create an empty database with reference data and LCIA methods
In the menu, click on Database → New database → From scratch..., input a database name and select
Complete reference data before clicking on Finish.
This will create an empty database with the reference data. For more information, see Creating a new database from scratch.
Once the database is created, download the openLCA LCIA methods package from Nexus and import it into the database you have created. For more information, see Importing LCIA methods into openLCA.
This database is often a good starting point to start modeling with the Python interface (and in openLCA more generally).
Create the product system from scratch
Now that you have created a database and opened it, you will be able to interact with its datasets
via the Python script. The routine is quite simple: create datasets and add them to the database
(db.insert) or retrieve them from the database (db.getForName or db.get).
NOTE: You can run the following lines of code by copy-pasting them in the openLCA Python console. You can also copy the whole script.
First, let's create a flow representing Boiling water, using a Volume as dimension. The
FlowProperty tells the system how to measure the quantity of this flow–i.e. in any unit of volume
(liters or cubic meters, ... ).
volume = db.getForName(FlowProperty, "Volume")
boiling_water = Flow.product("Boiling water", volume)
In the first line, the flow property for volumes is retrieved from the database (more details about it in The basic data model chapter). In the second line, the product flow is created with its name and its flow property.
It is now time to create the process for boiling water with an electric kettle. Let's create a process with its name and its reference flow.
boiling_water_kettle = Process.of(
"Boiling water with an electric kettle", boiling_water
)
Let's now add inputs to the process. First, we can retrieve the Water elementary flow from the reference data. Second, we create a flow for the electricity needed for the kettle and add it to the process.
water = db.getForName(Flow, "Water")
boiling_water_kettle.input(water, 0.001) # m3
energy = db.getForName(FlowProperty, "Energy")
electricity = Flow.product("Electricity", energy)
boiling_water_kettle.input(electricity, 0.35) # MJ
The next step is to create a process for the electricity production. We will call it Electricity production and make it really simple for the sake of the example.
electricity_production = Process.of("Electricity production", electricity)
coal = db.getForName(Flow, "Coal, hard, unspecified")
electricity_production.input(coal, 0.05) # kg
Now that all the elements needed to build the product system are created, it is time to insert them in the database.
db.insert(boiling_water, electricity, boiling_water_kettle, electricity_production)
We can now create the product system. Now that it is important to insert the processes and the flows
before running the ProductSystem.link method. If you run the ProductSystem.link method before
inserting the processes and the flows, openLCA won't be able to correctly link the processes.
system = ProductSystem.of("Boiling water with an electric kettle", boiling_water_kettle)
system.link(coal, boiling_water_kettle)
db.insert(system)
After the two first lines, the system only exist in memory. To store it in the database, we need to
run the db.insert method. It will also insert the processes and the flows in the database.
After running this code, refresh the navigator by clicking on the tree dot and then on Refresh. The newly created flow, processes and product system should appear in their respective folder.
Run a calculation
To run a calculation, we need to create a calculation setup with the product system that we have
created in the previous section as well as the EPD 2018 impact method. The calculation is then run
with the SystemCalculator class.
method = db.getForName(ImpactMethod, "EPD 2018")
setup = CalculationSetup.of(system).withImpactMethod(method)
result = SystemCalculator(db).calculate(setup)
Now that the calculation has been run, we can access the results. For example, we can get the total impact value of the Abiotic depletion, fossil fuels impact category.
categories = list(method.impactCategories)
impact = next(i for i in categories if i.name == "Abiotic depletion, fossil fuels")
value = result.getTotalImpactValueOf(Descriptor.of(impact))
print(
"The total impact on %s for %s is %.3f %s."
% (impact.name, system.name, value, impact.referenceUnit)
)
# Output:
# The total impact on Abiotic depletion, fossil fuels for Boiling water with
# an electric kettle is 0.318 MJ.
In this first section, we have seen how to create flows and processes to build a product system and how to run a calculation. In the following chapter, we will understand the data model the relationship between flows, processes and product systems in more details.
Data model
This section covers the structure of data in openLCA. It starts with the basic data model, explaining core concepts. Then, it shows how to create a product system from a process before exploring the advanced data model for more complex cases. Understanding these concepts will help you work efficiently with openLCA in general.
The basic data model
The basic data model of openLCA is defined in the package org.openlca.core.model of the
olca-core module. When you work
with data in openLCA you will usually interact with the types of this package. In this section, we
describe the basic data types and how they are related to each other. Each type is basically a Java
class which you can access like a normal Python class from Jython.
Note that we will not describe all types of the openLCA model and we will focus on the most important properties.
NOTE: You can run the following lines of code by copy-pasting them in the openLCA Python console. You can also copy the whole script.
The basic inventory model
The openLCA data model is built around a basic inventory model which has the following components:
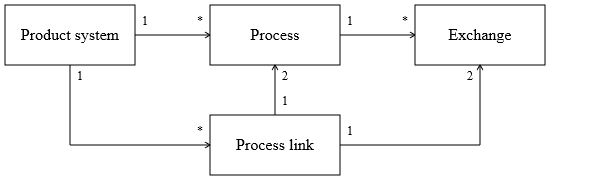
In this model, processes are the basic building blocks that describe the production of a material or energy, treatment of waste, provision of a service, etc. Each process has a set of exchanges that contain the inputs and outputs of flows like products, wastes, resources, and emissions of that process. The product and waste flows can be linked in a product system to specify the supply chain of a product or service: the functional unit of that product system. Such product systems are then used to calculate inventory and impact assessment results.
Units and unit groups
All quantitative amounts of the inputs and outputs in a process have a unit of measurement. In openLCA convertible units are organized in groups that have a reference unit to which the conversion factors of the units are related:
class Unit:
name: str
description: str
conversionFactor: float
synonyms: str
...
class UnitGroup:
name: str
description: str
referenceUnit: Unit
units: List[Unit]
defaultFlowProperty: FlowProperty
...
Units and unit groups can be created in the following way:
kg = Unit.of("kg", 1.0) # name: str, conversionFactor: float
units_of_mass = UnitGroup.of("Unit of mass", kg) # name: str, referenceUnit: Unit
units_of_mass.units.add(kg)
Flows and flow properties
Flows are the things that are moved around as inputs and outputs (exchanges) of processes. When a process produces electricity and another process consumes electricity from the first process, both processes will have an output exchange and input exchange with a reference to the same flow. The basic type definition of a flow looks like this:
class Flow:
name: str
description: str
flowType: FlowType
referenceFlowProperty: FlowProperty
flowPropertyFactors: List[FlowPropertyFactor]
formula: str
location: Location
infrastructureFlow: bool
synonyms: str
...
The flow type
The flowType property indicates whether the flow is a product, waste, or elementary flow. Product
and waste flows can link inputs and outputs of processes (like electricity) in a product system
where elementary flows (like CO₂) are the emissions and resources of the processes. Basically, in
the calculation the flow type is used to decide whether to put an exchange amount into the
technology matrix A or the intervention matrix B (see also the calculation section).
The type FlowType is an enumeration type with the following values:
PRODUCT_FLOW,ELEMENTARY_FLOW,WASTE_FLOW.
When you create a flow, you can set the flow type in the following way:
flow = Flow()
flow.flowType = FlowType.PRODUCT_FLOW
flow.name = "Liquid aluminium"
NOTE: We will see in the Processes section a even easier way to create flows.
Flow properties
A flow in openLCA has physical properties (like mass or volume), called flow properties, in which the amount of a flow in a process exchange can be specified:
class FlowProperty:
name: str
description: str
refId: str
flowPropertyType: FlowPropertyType
unitGroup: UnitGroup
...
Like the FlowType the FlowPropertyType is an enumeration type and can have the following values:
PHYSICAL and ECONOMIC. The flow property type is basically only used when physical and economic
allocation factors of a process are calculating automatically. With this, a flow property can be
created in the following way:
mass = FlowProperty()
mass.flowPropertyType = FlowPropertyType.PHYSICAL
mass.unitGroup = units_of_mass
# the same operation can be done using the FlowProperty.of method as the
# default flow property type is PHYSICAL
mass = FlowProperty.of("Mass", units_of_mass) # name: str, unitGroup: UnitGroup
For a flow, all flow properties need to be convertible by a factor which is defined by the type
FlowPropertyFactor:
class FlowPropertyFactor:
conversionFactor: float
flowProperty: FlowProperty
...
These conversion factors are related to the reference flow property (referenceFlowProperty) of the
flow:
flow.referenceFlowProperty = mass
massFactor = FlowPropertyFactor.of(mass, 1.0) # prop: FlowProperty, factor: float
flow.flowPropertyFactors.add(massFactor)
Processes
A process describes the inputs and outputs (exchanges) related to a quantitative reference which is typically the output product of the process:
class Process:
name: str
description: str
refId: str
quantitativeReference: Exchange
exchanges: List[Exchange]
defaultAllocationMethod: AllocationMethod
allocationFactors: List[AllocationFactor]
processType: ProcessType
location: Location
documentation: ProcessDoc
infrastructureProcess: bool
socialAspects: List[SocialAspect]
dqSystem: DQSystem
socialDqSystem: DQSystem
...
An input or output is described by the type Exchange in openLCA:
class Exchange:
input: bool
flow: Flow
unit: Unit
amountValue: float
defaultProviderId: long
formula: str
uncertainty: Uncertainty
baseUncertainty: float
dqEntry: str
cost: float
costFormula: str
currency: Currency
isAvoided: bool
...
The Boolean property input indicates whether the exchange is an input (True) or not (False).
Each exchange has a flow (like steel or CO₂), unit, and amount but also a flow property factor which
indicates the physical quantity of the amount (note that there are different physical quantities
that can have the same unit). The following example shows how we can create a process and define its
quantitative reference as a product output:
output = Flow.product("Molten aluminium", mass) # name: str, flowProperty: FlowProperty
# create a process with `output` as quantitative reference with the default amount of 1.0
process = Process.of("Aluminium smelting", output)
To add inputs to the process, we create a flow (here a waste flow) and add it to the process as follows:
waste = Flow.waste(
"Spent Pot Lining (SPL)", mass
) # name: str, flowProperty: FlowProperty
process.input(waste, 4.2) # flow: Flow, amount: float
To change the amount of an exchange, we can fetch the exchange from the list and modify the amount value:
exchange = next(e for e in process.exchanges if e.flow.name == "Molten aluminium")
exchange.amount = 4.2
Product systems
A product system describes the supply chain of a product (the functional unit).
class ProductSystem:
name: str
description: str
refId: str
processes: List[Process]
referenceProcess: Process
quantitativeReference: Exchange
targetAmount: float
targetUnit: Unit
targetFlowPropertyFactor: FlowPropertyFactor
processLinks: List[ProcessLink]
referenceExchange: Exchange
parameterSets: List[ParameterRedefSet]
cutoff: float
analysisGroups: List[AnalysisGroup]
...
A product system can be created from an existing process in the following way:
system = ProductSystem.of("Aluminium smelting", process)
# name: str, process: Process
The process is added to the list of processes of the product system, the reference process is
set to the process, and the quantitative reference is set to the output exchange of the process. The
target attributes are also set using the process attributes.
To insert all the datasets in the database, you can use the db.insert method. Please note that the
order of the arguments is important: they are ordered by dependencies.
db.insert(units_of_mass, mass, flow, output, waste, process, system)
However, the product system created with this method is not yet linked to any provider. To do so, refer to the following section.
Impact methods
An impact method is used to translate environmental flows (like emissions and resource use) into potential environmental impacts, such as climate change or human toxicity.
class ImpactMethod:
name: str
description: str
refId: str
code: str # e.g. "EF 3.0" for Environmental footprint 3.0
impactCategories: List[ImpactCategory]
nwSets: List[NWSet]
source: Source
...
An impact category is a collection of impact factors that are used to calculate the potential environmental impact of an exchange:
class ImpactCategory:
name: str
description: str
refId: str
code: str # e.g. "GWP" for Global Warming Potential
impactFactors: List[ImpactFactor]
referenceUnit: str
direction: Direction
...
class ImpactFactor:
flow: Flow
value: float
flowPropertyFactor: FlowPropertyFactor
unit: Unit
formula: str
uncertainty: Uncertainty
location: Location
...
For the sack of completeness, the following example shows how to create an impact method with impact categories. Note that in general you will not need to create impact methods and impact categories in Python. You will rather get the impact methods from the method package.
bromopropane = Flow.product("Bromopropane", mass)
butane = Flow.product("Butane", mass)
impact_category = ImpactCategory.of(
"Climate change", "kg CO2-Eq"
) # name: str, referenceUnit: str
impact_category.factor(bromopropane, 0.052) # flow: Flow, value: float
impact_category.factor(butane, 0.006) # flow: Flow, value: float
impact_method = ImpactMethod.of("EF 3.0") # name: str
impact_method.add(impact_category)
Building a product system from a process
openLCA provides the option to create a product system from a process. The same operation can be
done from the Python editor as well. Similar settings (preferred providers, process type) can be set
with the LinkingConfig object. To run the following code in the openLCA Python editor, you need to
open an ecoinvent database (here ecoinvent v3.10.1 APOS).
process = db.getForName(Process, "gold production | gold | APOS, U")
if not isinstance(process, Process):
raise Exception("Process not found")
config = (
LinkingConfig()
.providerLinking(ProviderLinking.PREFER_DEFAULTS)
.preferredType(LinkingConfig.PreferredType.UNIT_PROCESS)
)
system = ProductSystemBuilder(db, config).build(process)
Once again, you need to run db.insert(system) to store the product system in the database.
The ProviderLinking indicates how default providers of product inputs or waste outputs in
processes should be considered in the linking of a product system. It is define as follows:
class ProviderLinking(Enum):
IGNORE_DEFAULTS,
PREFER_DEFAULTS,
ONLY_DEFAULTS,
IGNORE_DEFAULTS: Default provider settings are ignored in the linking process. This means that the linker can also select another provider even when a default provider is set.PREFER_DEFAULTS: When a default provider is set for a product input or waste output the linker will always select this process. For other exchanges it will select the provider according to its other rules.ONLY_DEFAULTS: Means that links should be created only for product inputs or waste outputs where a default provider is defined which are then linked exactly to this provider.
The PreferredType indicates which type of process should be used to link the product system. It is
defined as follows:
enum PreferredType(Enum):
UNIT_PROCESS,
SYSTEM_PROCESS,
RESULT
Advanced data model
Categories
class Category:
name: str
modelType: ModelType
category: Category
childCategory: List[Category]
...
A category is a path that is used to group entities (flows, processes, ...) together. For example,
the category of a flow Emission to air/unspecified/Chromium VI is unspecified and the category
of unspecified is Emission to air:
print(chromium6.category.name) # prints: unspecified
print(chromium6.category.category.name) # prints: Emission to air
To create a category and more generally a full path, we use the CategoryDao.sync method. It will
create the categories if they do not exist and return the category of the last segment.
emission_unspecified = CategoryDao.sync(db, ModelType.FLOW, "Emission to air", "unspecified")
chromium6.category = emission_unspecified
Parameters
In openLCA, parameters can be defined in different scopes: global, process, or LCIA method. The parameter name can be used in formulas and, thus, need to conform to a specific syntax. Within a scope the parameter name should be unique (otherwise the evaluation is not deterministic). There are two types of parameters in openLCA: input parameters and dependent parameters. An input parameter can have an optional uncertainty distribution but not a formula. A dependent parameter can (should) have a formula (where also other parameters can be used) but no uncertainty distribution.
class Parameter:
name: str
scope: ParameterScope
isInputParameter: bool
value: float
uncertainty: Uncertainty
formula: str
...
Parameters can be created in the following way:
# create a global input parameter
g = Parameter.global("number_of_items", 42.0) # name: str, value: float
# create a process input parameter
process = Process()
p = Parameter.process("output_volume", 2.4) # name: str, value: float
# create a LCIA method dependent parameter
# name: str, formula: str
impact_category = ImpactCategory()
i = Parameter.impact("impact_value", "2 * number_of_items")
Meta classes
RootEntity
The RootEntity is the base class for all entities (flows, processes, units, unit groups, ...). A
RefEntity is an entity that can be referenced by a unique ID, the reference ID or short refId.
class RootEntity:
name: str
refId: str
description: str
...
Descriptors
Descriptors are lightweight models containing only descriptive information of a corresponding entity. The intention of descriptors is to get this information fast from the database without loading the complete model. Checkout the Interacting with the database chapter for more information.
class Descriptor: # or RootDescriptor
name: str
refId: str
version: long
lastChange: long
library: str # contains the library identifier
tags: str
type: ModelType
...
FlowDescriptor
The FlowDescriptor class extends the RootDescriptor class and adds the flow type, location as
well as the reference flow property ID.
class FlowDescriptor:
name: str
refId: str
version: long
lastChange: long
library: str # contains the library identifier
tags: str
type: ModelType
flowType: FlowType
location: long
refFlowPropertyId: long
...
LocationDescriptor
The LocationDescriptor class extends the RootDescriptor class and adds the location code.
class LocationDescriptor:
name: str
refId: str
version: long
lastChange: long
library: str # contains the library identifier
code: str
ImpactDescriptor
The ImpactDescriptor class extends the RootDescriptor class and adds the reference unit and the
direction.
class ImpactDescriptor:
name: str
refId: str
version: long
lastChange: long
library: str # contains the library identifier
referenceUnit: str
direction: Direction
To go further
Java source code
The olca-modules repository
You can find the detail of every data type of openLCA in the source code of the application. The repository is open source and you can browse the code yourself. The repository is available at github.com/GreenDelta/olca-modules.
The module containing the data model of openLCA is called olca-core. You can find the folder with
all the classes in
model.
Example
For example, if you wonder how to add normalization and weighting set to an impact method, you can find how to create a normalization and weighting set and add it.
- find the
ImpactMethodclass and check how to add a normalization and weighting set. In that case, you will use theImpactMethod.add(nwSet) # nwSet: NwSetmethod. - find the
NwSetclass and check how to build it withNwSet.of(name) # name: strmethod. - realize that you need to add
factorto this newNwSetinstance with theNwSet.add(factor) # factor: NwFactormethod. - check out the
NwFactorclass and find how to create it with theNwFactor.of(impact, normalisationFactor, weightingFactor) # impact: ImpactCategory, normalisationFactor: float, weightingFactor: float
You can now create and add a normalization and weighting set to an impact method with the following code:
nwSet = NwSet.of("My new normalization and weighting set")
nwSet.add(NwFactor.of(category_one, 4.2, 0.042))
nwSet.add(NwFactor.of(category_two, 2.4, 0.024))
method.add(nwSet)
Java first, then Jython
One helpful approach when working with Jython is to first write your code in Java and then translate it to Python syntax. This method can be very effective if you already have some experience with Java, as it allows you to reuse your knowledge of Java classes, method calls, and structure. You can use any Java IDE (like Eclipse or IntelliJ) to write your Java code first, which often makes debugging easier. Once your Java version looks good, you can convert it step by step into Python code that runs on the Jython interpreter.
Interacting with the database
To do anything meaningful in openLCA via scripting—like accessing flows, processes, product systems, or results—you need to interact with the database. This chapter introduces the main ways to do that:
-
Using the db variable, a pre-defined connection to the currently opened database.
-
Accessing data through DAOs (Data Access Objects), the recommended and structured way to query model elements.
-
Writing custom SQL queries for advanced or performance-critical operations.
The db object
By default, a variable named db is automatically available for use when opening the Python editor.
This variable is of type Db and represents the openLCA database. You can use the database in the
following way:
db.get(modelType, id)gets an object of typemodelTypefrom the databasedb.getAll(modelType)gets all objects of typemodelTypefrom the databasedb.getForName(modelType, name)gets the arbitrary first object of typemodelTypewith namenamedb.getDescriptor(modelType, id)gets a descriptor of typemodelType(useful for heavy datasets)db.getDescriptors(modelType)gets all descriptors of typemodelTypedb.insert(object)inserts the object into the databasedb.delete(object)deletes the object from the databasedb.update(object)updates the object in the database
Some basic examples
# get the mass flow property
mass = db.get(FlowProperty, 'Mass')
# insert a newly created process
process = Process.of('Aluminium smelting', mass)
db.insert(process)
process.description = 'Process for smelting aluminium'
# update the process
db.update(process)
# delete the process
db.delete(process)
More functionalities with DAO
db has its own limits when it comes to getting datasets with a specific name. To get a list of the
datasets with a specific name, you can use the model DAO. Each model has its own model DAO:
ProcessDao, FlowDao, ProductSystemDao, etc.
DAO can be used with the following methods:
ModelDao(db).getForName(name)gets all the datasets with the namenameModelDao(db).getAll()gets all the datasetsModelDao(db).deleteAll()deletes all the datasets (use with caution)
For example, to get all the processes with the name Aluminium smelting:
processes = ProcessDao(db).getForName('Aluminium smelting')
Running SQL queries
You can run SQL queries on the database using the NativeSql class. You will need to create a
handler function to collect the results that return True to continue the query, or False to stop
it.
For example to collect all the processes that have Trichlorofluoromethane as output:
flows = FlowDao(db).getForName('Trichlorofluoromethane')
processes = [] # List[str]
def collect_results(record):
process = db.get(Process, record.getLong(1))
processes.append(process.name)
return True
for flow in flows:
query = (
"SELECT f_owner FROM tbl_exchanges WHERE f_flow = %i AND is_input = 0"
% flow.id
)
NativeSql.on(db).query(query, collect_results)
print("\n".join(processes))
Interacting with the openLCA UI
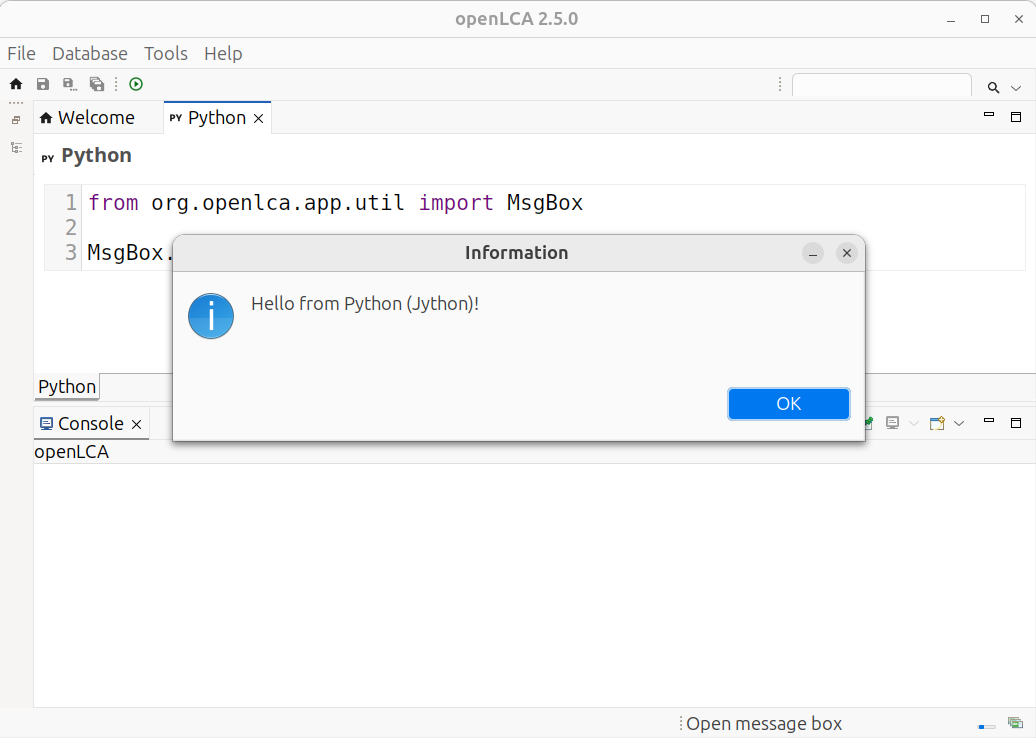
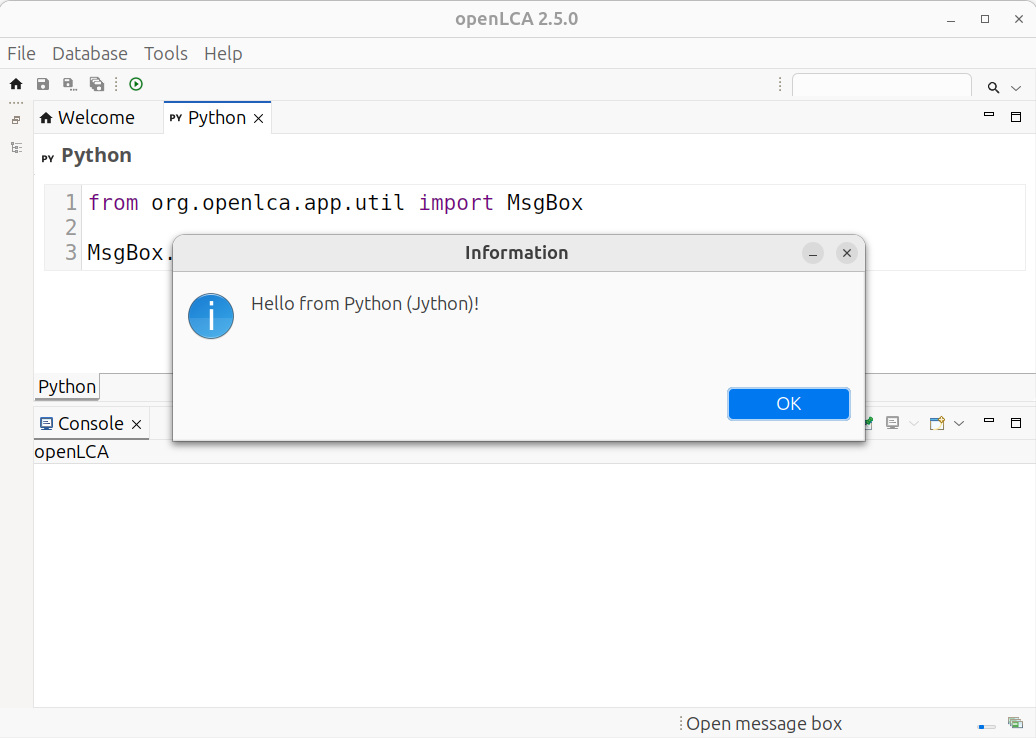
The script is executed in the same Java process as openLCA. Thus, you have access to all the things that you can do with openLCA via this scripting API (and also to everything that you can do with the Java and Jython runtime). Here is a small example script that will show the information message box when you execute it in openLCA:
from org.openlca.app.util import MsgBox
MsgBox.info("Hello from Python (Jython)!")
Calculation and results
Once your product system is ready, the next step is to perform the calculation and explore the results. This section explains how to run the calculation in Jython and how to work with the result object to inspect impacts, flows, and contributions.
Calculation and results
After you've completed the modeling of your processes, created your product system, it's time to run a calculation.
For demonstration purposes, we create a calculation setup for a product system of an ecoinvent process and run it.
Getting an impact method
The impact method can be retrieved from the database using the db.getForName method:
method = db.getForName(ImpactMethod, "EF v3.1")
Running a calculation
The calculation of a product system is done by creating a calculation setup and running the
calculate method of the SystemCalculator. The calculation setup is an object that contains all
the information needed for the calculation:
- the target product system or process,
- the amount of the functional unit,
- the LCIA method,
- the normalization and weighting sets,
- the parameter redefinitions,
- the allocation method,
- with or without costs,
- with and without regionalization,
- ...
setup = CalculationSetup.of(system).withAmount(4.2).withImpactMethod(method)
result = SystemCalculator(db).calculate(setup)
for impact in result.getTotalImpacts():
print(
"%s: %.3f %s"
% (impact.impact().name, impact.value(), impact.impact().referenceUnit)
)
LcaResult object
The result of the calculation is a LcaResult object. It provides an interface for accessing impact
factors, total flows, and contributions and many other objects in a structured way. The manual won't
cover all the accessible methods of the LcaResult object. For more information, please refer to
the
class
itself.
For the following examples, let's assume we have calculated the results of a product system under
the Python variable result.
Specific setup options
Normalization and weighting set
The withNwSet method allows to specify a normalization and weighting set. The normalization and
weighting set can be retrieved from the database by using the ImpactMethod object:
nw_sets = method.nwSets
nw_set = next(
nw_sets for nw_sets in nw_sets if nw_sets.name == "EF v3.1 | Global Reference 2010"
)
setup.withNwSet(nw_set)
Parameter redefinitions
The parameters of a product system can be redefined using the withParameters method. For example,
you can replace the value of a global input parameter with a new value:
g = db.getForName(Parameter, "g")
parameters = [ParameterRedef.of(g, 1.62)]
setup.withParameters(parameters)
Parameter redefinition set
You can select one of the product system parameter redefinition sets to use with the in the calculation setup:
assert "Scenario 1" in [p.name for p in system.parameterSets]
setup.withParameterSetName("Scenario 1")
Allocation method
The allocation method can be selected among the following options:
class AllocationMethod:
USE_DEFAULT,
CAUSAL,
ECONOMIC,
NONE,
PHYSICAL,
The default allocation method is AllocationMethod.USE_DEFAULT. To use a different allocation
method, you can use the withAllocationMethod method:
setup.withAllocationMethod(AllocationMethod.CAUSAL)
Other options
With or without costs
When running an LCC (Life Cycle Costing) calculation on a product system with costs, the costs can
be included in the calculation with the withCosts method:
setup.withCosts(True) # default is False
With or without regionalization
With openLCA you can perform regionalized impact assessment, accounting for specific conditions and
characteristics of the location where the processes occur. To enable regionalization, you can use
the withRegionalization method:
setup.withRegionalization(True) # default is False
Technosphere flows
To retrieve the technosphere matrix, use the techIndex method. It will return an iterator of
TechFlows: TechIndex, which maps symmetrically the rows (products or wastes) and columns
(process, product systems, ...) of the technology matrix.
class TechFlow:
def provider(): # () -> RootDescriptor
def flow(): # () -> FlowDescriptor
NOTE: More information about
RootDescriptorandFlowDescriptorcan be found in the The advanced data model chapter.
You can create a TechFlow object by calling the TechFlow.of method. When using the method on a
process, it will return a tech-flow from the given process with the quantitative reference. When
using the method on a product system, it will return a tech-flow from the given product system with
the reference of that system.
tech_flow = TechFlow.of(provider, flow) # (Process, Flow) -> TechFlow
tech_flow = TechFlow.of(process) # (Process) -> TechFlow
tech_flow = TechFlow.of(system) # (ProductSystem) -> TechFlow
tech_index = result.techIndex()
for tech_flow in tech_index:
print(
"Provider: %s\nFlow: %s\n" % (tech_flow.provider().name, tech_flow.flow().name)
)
Total requirements
To get the total requirements of a technosphere flow, we use the getTotalRequirementsOf method. It
will return the total amount of the flow required by the corresponding provider.
tech_index = result.techIndex()
for tech_flow in tech_index:
print(
"The flow %s in %s requires a total amount of %s\n"
% (
tech_flow.flow().name,
tech_flow.provider().name,
result.getTotalRequirementsOf(tech_flow),
)
)
Scaled technosphere flows
The scaled technosphere flows of a process are the scaled inputs and outputs of the linked product
and waste flows of that process related to the final demand of the product system. They can be
obtained with the getScaledTechFlowsOf method. It will return a list of TechFlowValue, which is
a record:
class TechFlowValue:
def techFlow(): # () -> TechFlow
def value(): # () -> float
For example, to get the scaled technosphere flows amount of the first process in the technosphere matrix:
tech_flow = TechFlow.of(system)
scaled_tech_flows = result.getScaledTechFlowsOf(tech_flow)
for tech_flow_value in scaled_tech_flows:
print(
"The scaled amount of %s is %s."
% (tech_flow_value.techFlow().flow().name, tech_flow_value.value())
)
Unscaled technosphere flows
The unscaled requirements of a process are the direct requirements of the process related to the quantitative reference of that process without applying a scaling factor. For example, the unscaled amount of the flows of the last column:
scaled_tech_flows = result.getUnscaledTechFlowsOf(tech_flow)
for tech_flow_value in scaled_tech_flows:
print(
"The scaled amount of %s is %s."
% (tech_flow_value.techFlow().flow().name, tech_flow_value.value())
)
For more...
For more specific methods, please refer to the
LcaResult class.
Intervention flows
The intervention flows are the flows that cross the boundary with the environment of the calculated
system (this is why the short name is EnviFlow).
To retrieve the intervention matrix, we use the enviIndex method. It will return an iterator of
EnviFlows: EnviIndex, which maps symmetrically the rows (intervention flows) and columns
(technosphere flows).
class EnviFlow:
def flow(): # () -> FlowDescriptor
def location(): # () -> LocationDescriptor
def isInput(): # () -> bool
def wrapped(): # () -> Descriptor
NOTE: More information about
LocationDescriptor,FlowDescriptorandDescriptorcan be found in the The advanced data model chapter.
You can create an EnviFlow object by calling the EnviFlow.inputOf and EnviFlow.outputOf
methods.
envi_flow = EnviFlow.inputOf(flow_descriptor) # (FlowDescriptor) -> EnviFlow
envi_flow = EnviFlow.outputOf(flow_descriptor) # (FlowDescriptor) -> EnviFlow
envi_index = result.enviIndex()
for envi_flow in envi_index:
print("Flow: %s\nIs input? %s\n" % (envi_flow.flow().name, envi_flow.isInput()))
Inventory results
To get the inventory results, the quantitative list of all the material and energy flows into and
out of the system boundary, we use the getTotalFlows method. It will return a list of
EnviFlowValue, which is a record of an EnviFlow and the amount of the flow.
class EnviFlowValue:
def enviFlow(): # () -> EnviFlow
def value(): # () -> float
envi_flow_values = result.getTotalFlows()
for envi_flow_value in envi_flow_values:
in_or_out = "input" if envi_flow_value.isInput() else "output"
print(
"The total amount of the %s %s is %s."
% (in_or_out, envi_flow_value.flow().name, envi_flow_value.value())
)
Direct contributions
To get the direct contributions of a each process to the inventory result of a flow, we use the
getDirectFlowValuesOf method. It will return a list of TechFlowValue.
envi_flow = EnviFlow.inputOf(flow_descriptor)
contributions = result.getDirectFlowValuesOf(envi_flow)
for contribution in contributions:
print(
"The contribution of %s is %s."
% (contribution.techFlow().flow().name, contribution.value())
)
Total values
The total value of a flow for a given process is the total inventory result at this point of the supply chain. It includes the direct, upstream, and downstream (related to waste treatment) contributions.
envi_flow = EnviFlow.inputOf(flow_descriptor)
total_values = result.getTotalFlowValuesOf(envi_flow)
for total_value in total_values:
print(
"The total value of %s is %s."
% (total_value.techFlow().flow().name, total_value.value())
)
Direct process results
The direct process results are the direct intervention flows of a process to fulfill the demand of the product system.
tech_flow = TechFlow.of(provider, flow)
envi_flow_values = result.getDirectFlowsOf(tech_flow)
for envi_flow_value in envi_flow_values:
print(
"The direct amount of %s is %s."
% (envi_flow_value.enviFlow().flow().name, envi_flow_value.value())
)
And more...
For more specific methods, please refer to the
LcaResult class.
Impact categories
Impact assessment result
In order to get the results of an impact assessment, we use the getTotalImpacts method. It will
return a list of ImpactValues.
class ImpactValue:
def impact(): # () -> ImpactDescriptor
def value(): # () -> float
NOTE: More information about
ImpactDescriptorcan be found in the The advanced data model chapter.
impact_values = result.getTotalImpacts()
for impact_value in impact_values:
print(
"The total impact on %s is %s %s."
% (
impact_value.impact().name,
impact_value.value(),
impact_value.impact().referenceUnit,
)
)
Normalized impact assessment result
In order to get the normalized results of an impact assessment, we use the normalize method of the
NwSetTable:
impact_values = result.getTotalImpacts()
assert setup.nwSet() is not None
factors = NwSetTable.of(db, setup.nwSet())
normalized_impact_values = factors.normalize(impact_values)
for impact_value in normalized_impact_values:
print(
"The normalized impact on %s is %s."
% (
impact_value.impact().name,
impact_value.value(),
)
)
Weighted impact assessment result (TODO)
In order to get the weighted results of an impact assessment, we use the apply method of the
NwSetTable:
impact_values = result.getTotalImpacts()
assert setup.nwSet() is not None
factors = NwSetTable.of(db, setup.nwSet())
weighted_impact_values = factors.apply(impact_values)
for impact_value in weighted_impact_values:
print(
"The weighted impact on %s is %s."
% (
impact_value.impact().name,
impact_value.value(),
)
)
Direct contributions
To get the direct contributions of a each process to the impact result of an impact category, we use
the getDirectImpactValuesOf method. It will return a list of TechFlowValue.
climate_change = next(c for c in method.impactCategories if c.name == "Climate change")
contributions = result.getDirectImpactValuesOf(Descriptor.of(climate_change))
for contribution in contributions:
print(
"The contribution of %s in %s is %s ."
% (
contribution.techFlow().flow().name,
contribution.techFlow().provider().name,
contribution.value(),
)
)
Direct process results
The direct process results are the direct impacts of a process in the calculated product system. We
use the getDirectImpactsOf method. It will return a list of ImpactValues.
impacts = result.getDirectImpactsOf(tech_flow)
for impact in impacts:
print(
"The direct impact on %s is %s %s."
% (
impact.impact().name,
impact.value(),
impact.impact().referenceUnit,
)
)
Total process results
The total process results are the total impacts of a process in the calculated product system at the
stage of the supply chain. It takes into account the direct, upstream, and downstream impacts. We
use the getTotalImpactsOf method. It will return a list of ImpactValues.
impacts = result.getTotalImpactsOf(tech_flow)
for impact in impacts:
print(
"The total impact on %s is %s %s."
% (
impact.impact().name,
impact.value(),
impact.impact().referenceUnit,
)
)
Contribution tree
As you probably know from using the Contribution tree tab in openLCA, it is a visual representation of the environmental impacts of a system across its entire supply chain. It helps identify which stages of the life cycle contribute most to the overall environmental impact.
The contribution tree can be obtained from the LcaResult object by using the UpstreamTree.of
method. It takes a ResultProvider as well as an EnviFlow or ImpactDescriptor (see
Advanced data model) object as input. Let's build one:
Getting an upstream tree
climate_change = next(i for i in method.impactCategories if i.name == "Climate change")
tree = UpstreamTree.of(result.provider(), Descriptor.of(climate_change))
The UpstreamTree is composed of UpstreamNode objects. Each UpstreamNode provides different
types of result and the provider (TechFlow). The root node of the tree can be retrieved via the
UpstreamTree.root attribute. And the children of a node can be retrieved via the
UpstreamTree.childs method.
class UpstreamNode
def provider(): # () -> TechFlow
"""Returns the provider of the product output or waste input of this upstream tree node."""
def result(): # () -> float
"""Returns the upstream result of this node."""
def requiredAmount(): # () -> float
"""Returns the required amount of the provider flow of this upstream node."""
def scalingFactor(): # () -> float
"""Returns the scaling factor of this upstream node."""
def directContribution(): # () -> float
"""
Returns the direct contribution of the process (tech-flow) of the node to the total
result the node.
"""
Traversing the tree, breath-first
The tree can be traversed using the UpstreamTree.childs method recursively. A good practice is to
set a maximum depth to avoid long computation times.
DEPTH = 5
UNIT = climate_change.referenceUnit
def traverse(tree, node, depth):
if depth == 0:
return
print(
"%sThe impact result of %s is %s %s (%s%%)."
% (
" " * (DEPTH - depth),
node.provider().provider().name,
node.result(),
UNIT,
node.result() / tree.root.result() * 100,
)
)
for child in tree.childs(node):
traverse(tree, child, depth - 1)
traverse(tree, tree.root, DEPTH)
Costs
The LCC (Life Cycle Costing) results are only available if the system has been calculated with the
withCosts(True) method applied.
Life cycle costing result
To get the life cycle costing results, we use the getTotalCosts method. It will return the total
cost of the system as a float.
currency = system.referenceExchange.currency.name
total_cost = result.getTotalCosts()
print("The total cost of the system is %s %s." % (total_cost, currency))
Direct contributions
Similar to the direct contributions of the inventory, we can get the direct contributions of a
process to the life cycle cost of the system with the getDirectCostValues method. It will return a
list of TechFlowValue. For example:
contributions = result.getDirectCostValues()
for contribution in contributions:
print(
"The contribution of %s in %s is %s %s."
% (
contribution.techFlow().flow().name,
contribution.techFlow().provider().name,
contribution.value(),
currency,
)
)
Total values
Similar to the total values of the inventory, we can get the total costs of a process at a point in the supply chain. It will take into account the direct, upstream and downstream costs.
total_costs = result.getTotalCostValues()
for total_cost in total_costs:
print(
"The total cost of %s in %s is %s %s."
% (
total_cost.flow().name,
total_cost.provider().name,
total_cost.value(),
currency,
)
)
Analysis groups
With analysis groups, you can categorize your product system's processes into various categories allowing later to group results (see openLCA manual).
Get the analysis groups
The AnalysisGroup type contains the name and color of the analysis group and a set of processes.
class AnalysisGroup:
name: str
color: str
processes: Set[long] # set of processes id
You can get the analysis groups information from the product system as follows:
form java.util import HashSet
for group in system.analysisGroups:
print("%s (%s)" % (group.name, group.color))
for process in HashSet(group.processes):
print(" - %s" % process)
Get the results for an analysis group
You can get the results for an analysis group as follows:
grouped_result = AnalysisGroupResult.of(system, result)
for category in categories:
impact_values = grouped_result.getResultsOf(Descriptor.of(category))
print(
"%s (Rest: %s %s):"
% (category.name, impact_values.get("Top"), category.referenceUnit)
)
for group in system.analysisGroups:
print(
" - %s: %s %s"
% (group.name, impact_values.get(group.name), category.referenceUnit)
)
Sankey graph
openLCA provides an API to gather all the data necessary to create a Sankey graph. The Sankey
class provides methods to gather this data. The Sankey diagram can be created to show the flow of
material as well as impacts in the product system. Here is an example of how to extract the data for
a maximum number of nodes MAX_NODES and a minimum share (relative impact of a provider on the
total impacts) MIN_SHARE.
First step is to build the Sankey diagram:
MAX_NODES = 50
MIN_SHARE = 0.1
climate_change = next(c for c in method.impactCategories if c.name == "Climate change")
impact_descriptor = Descriptor.of(climate_change)
sankey = (
Sankey.of(impact_descriptor, result.provider())
.withMinimumShare(MIN_SHARE)
.withMaximumNodeCount(MAX_NODES)
.build()
)
The Sankey diagram can then be traversed to get the data for each node. For that, we use the a
consumer method (this is quite specific to Java). The consumer method accepts the Sankey.Node
object and execute some operations with it.
class Sankey.Node:
index: int
product: TechFlow
total: float
direct: float
share: float
providers: List[Sankey.Node]
To work with the consumer function, we have to import the java.util.function.Consumer class.
from java.util.function import Consumer
from org.openlca.app.util import Labels
class AddNodeConsumer(Consumer):
def accept(self, node): # type: (Sankey.Node) -> None
print("\n %s" % (Labels.name(node.product)))
print(" ID: %s" % (node.product.provider().id))
print(" Total impact: %s" % (node.total))
print(" Direct impact: %s" % (node.direct))
print(" Relative share: %s" % (node.share))
print(" Cutoff: %s" % (MIN_SHARE))
print(" Providers:")
for n in node.providers:
print(" %s" % (n.product.provider().id))
sankey.traverse(AddNodeConsumer())
Integration with Excel
Read the value of a cell
The following code snippet shows how to open an Excel file and read the first cell of the first sheet:
from java.io import File
from org.apache.poi.ss.usermodel import WorkbookFactory
# This example reads an Excel file from this path
PATH = "/path/to/file.xlsx"
# Load the workbook from the file
workbook = WorkbookFactory.create(File(PATH))
# Get the first sheet (indices are 0 based)
sheet = workbook.getSheetAt(0)
# Now you can use the Excel utility to read values from the sheet
# again, the indices of rows and columns are 0 based
row = 0
column = 0
# Reading a string value from a cell
string = Excel.getString(sheet, row, column)
print("String value of cell A1: %s" % string)
# Reading a numeric value from a cell
number = Excel.getDouble(sheet, row + 1, column + 1)
print("Numeric value of cell B2: %d" % number)
# Finally, it is good to close the workbook to clean up resources
workbook.close()
Write one cell
The example below shows how to create an Excel file and write its first cell.
from java.io import FileOutputStream
from org.apache.poi.ss.usermodel import WorkbookFactory
# Path where the Excel file will be written
PATH = "/path/to/file.xlsx"
# Load the workbook from the file
workbook = WorkbookFactory.create(True)
# Create a new sheet
sheet = workbook.createSheet()
# Create the first row (index 0) and first cell (index 0)
# and set a string value inside it
row = sheet.createRow(0)
cell = row.createCell(0)
cell.setCellValue("Hello from openLCA!")
# Write the workbook content to the file
output_stream = FileOutputStream(PATH)
workbook.write(output_stream)
# Close the output stream to ensure data is properly saved
output_stream.close()
# Close the workbook to free resources
workbook.close()
Cheat sheet
Shortcut keys
Ctrl + Shift + Enter/Ctrl + Shift + Enterto run the code in the editorCtrl + X/Cmd + Xto cut a line or a selectionCtrl + C/Cmd + Cto copy a line or a selectionCtrl + V/Cmd + Vto paste a line or a selectionCtrl + Enter/Cmd + Enterto insert a new line below the current lineCtrl + //Cmd + /to comment/uncomment out a line or a selection
Update the navigation bar
As the navigation bar does not update automatically when running code in the editor, you can update it programmatically with:
App.runInUI("Update navigator", lambda: Navigator.refresh())
Clear the console
You can clear the console before running the code with the following command:
from org.eclipse.ui.console import ConsolePlugin
consoles = ConsolePlugin.getDefault().getConsoleManager().getConsoles()
console = next(c for c in consoles if c.getName() == "openLCA")
console.clearConsole()
You can add this script to your own directory (e.g.
~/openLCA-data-1.4/python/utils.py) and run it with the following command:
from utils import Console
Console.clear()
Display a diagram with HTML
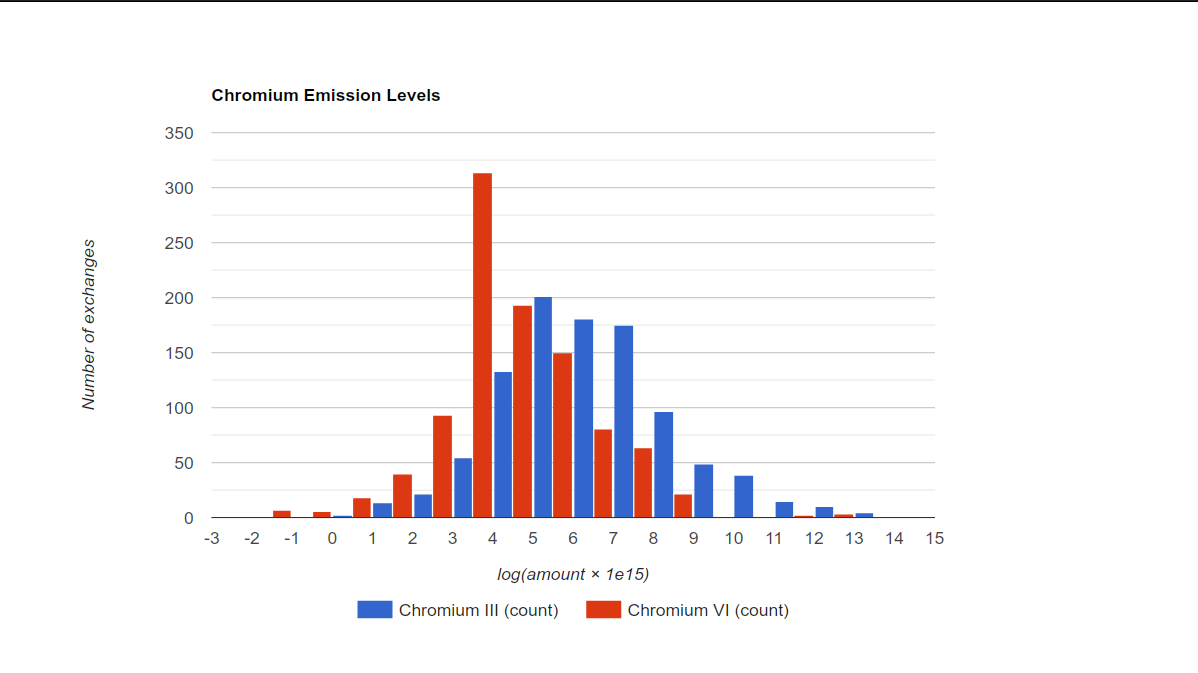
The following example shows how to display data in a diagram using HTML. In the example, all output
amounts of Emission to air/unspecified/Chromium III and Emission to air/unspecified/Chromium VI
are collected from a database, transformed with f(x) = log10(x * 1e15) to make a nice
distribution, and shown in a histogram using the
Google Chart API. An HTML
page is generated that is loaded in a SWT Browser in a separate window.
Retrieving the flow
The flows Chromium x are retrieved from the database by iterating over all flows named
Chromium x and then iterating over the categories of the flow.
To get all the flows name Chromium x, we use the FlowDao class. DAO stands for Data Access
Object, it is a class that provides access to the database without running complex SQL queries.
Every entities of openLCA has a category attribute that is a reference to the parent category. A
category can also have a parent category. In this example, we use the category hierarchy to filter
the flows. For each chromium name (Chromium VI, Chromium III), the following code is run:
def get_flow(name): # type: (str) -> Flow
"""
Get the flow `Emission to air / unspecified / Chromium ...` from the
database.
"""
flows = FlowDao(db).getForName(name)
for flow in flows:
c = flow.category
if c is None or c.name != "unspecified":
continue
c = c.category
if c is None or c.name != "Emission to air":
continue
return flow
Collecting the results
The amount of the output exchange of every process is collected from the database by running a SQL
query. The query is run using the NativeSql class, which is a wrapper around the database
connection.
def collect_amounts(flow): # type: (Flow) -> List[float or str]
results = [flow.name]
def collect_results(record):
results.append(math.log10(record.getDouble(1) * 1e15))
return True
print("Collecting results for {name}".format(**{"name": flow.name}))
query = (
"SELECT resulting_amount_value FROM tbl_exchanges WHERE f_flow = %i AND is_input = 0"
% flow.id
)
NativeSql.on(db).query(query, collect_results)
print("{size} results collected".format(**{"size": len(results) - 1}))
return results
Generating the HTML page
The HTML page is generated by injecting the results into a template.
Then, in order to display the page in a shell, we use the SWT Browser class. Yes! You can display
HTML pages in openLCA!
def make_html(results): # type: (List[List[float or str]]) -> str
"""Generate the HTML page for the data."""
html = """<html>
<head>
<script type="text/javascript" src="https://www.gstatic.com/charts/loader.js"></script>
<script type="text/javascript">
google.charts.load("current", {packages:["corechart"]});
google.charts.setOnLoadCallback(drawChart);
function drawChart() {
var data = google.visualization.arrayToDataTable(%s);
var options = {
title: 'Chromium Emission Levels',
legend: { position: 'bottom' },
hAxis: {
title: 'log(amount × 1e15)',
ticks: [%s]
},
vAxis: {
title: 'Number of exchanges'
}
};
var chart = new google.visualization.Histogram(
document.getElementById('chart_div')
);
chart.draw(data, options);
}
</script>
</head>
<body>
<div id="chart_div" style="width: 900px; height: 500px;"></div>
</body>
</html>
""" % (
json.dumps(results),
", ".join(str(x) for x in range(-3, 16)),
)
return html
Finally, the HTML page is loaded in a SWT Browser:
shell = Shell(Display.getDefault())
# set the window title
shell.setText("Chromium VI")
shell.setLayout(FillLayout())
browser = Browser(shell, SWT.NONE)
browser.setText(html)
shell.open()
To see the result, copy and paste the full script in the openLCA Python console in an opened ecoinvent database.
With ecoinvent 3.10.1 (APOS), the result looks like this:
Excel automation
This example shows how a tedious task can be automated using a spreadsheet and Jython.
Our use case is the following:
- We have a spreadsheet with a list of processes and their UUIDs.
- We want to create a product system for each process and run impact calculations on it.
- We want to store the results in a new sheet in the same spreadsheet.
An example spreadsheet can be downloaded here. It provides a list of processes from the ecoinvent v3.10.1 APOS database.
To follow this example with the full script, copy the content of this file.
Open the spreadsheet and gather the UUIDs
Checkout the Integration with Excel chapter for more details about how to open the spreadsheet.
The following code snippet will read the processes' name, UUIDS and amounts from the first sheet named "Processes". The callback function will print the process information to the console.
import string
from java.io import FileInputStream, FileOutputStream
from org.apache.poi.ss.usermodel import WorkbookFactory
# Do not forget to edit this path to point to your XLSX file!
PATH = "/path/to/excel/excel_automation.xlsx"
# Load the workbook from the file (using FileInputStream to be able to later write to it)
input_stream = FileInputStream(PATH)
workbook = WorkbookFactory.create(input_stream)
# Get the Processes sheet
sheet = workbook.getSheet("Processes")
# This function is an helper to use the cell names (A1, B1, C1, etc.) instead of their index
def get_cell(sheet, column, row): # type: (XSSFSheet, str, int) -> XSSFCell
column_label = string.ascii_uppercase.index(column)
return sheet.getRow(row).getCell(column_label)
def get_string_cell(sheet, column, row): # type: (XSSFSheet, str, int) -> str
return get_cell(sheet, column, row).getStringCellValue()
def get_numeric_cell(sheet, column, row): # type: (XSSFSheet, str, int) -> float
return get_cell(sheet, column, row).getNumericCellValue()
def get_process_info(sheet): # sheet: XSSFSheet -> Generator[dict[str, str or float]]:
for i in range(1, sheet.getLastRowNum() + 1):
name = get_string_cell(sheet, "A", i)
amount = get_numeric_cell(sheet, "B", i)
uuid = get_string_cell(sheet, "C", i)
yield {"name": name, "amount": amount, "uuid": uuid}
for process in get_process_info(sheet):
print(process)
workbook.close()
Create product systems and run impact calculations
Now that we have access the processes information, we can modify the script so that we create product systems and run impact calculations on them. The following code snippet will create a product system for each process and run impact calculations on it. The results are then printed to the console.
IMPACT_METHOD_ID = "67371e90-e11b-44e2-b7aa-039816c4e281"
def product_system_from_process(uuid): # type: (str) -> ProductSystem
process = db.get(Process, uuid)
if not isinstance(process, Process):
raise Exception("Process not found: " + uuid)
config = (
LinkingConfig()
.providerLinking(ProviderLinking.PREFER_DEFAULTS)
.preferredType(LinkingConfig.PreferredType.UNIT_PROCESS)
)
return ProductSystemBuilder(db, config).build(process)
def result_of_system(system, amount): # type: (ProductSystem, float) -> Result
method = db.get(ImpactMethod, IMPACT_METHOD_ID)
setup = CalculationSetup.of(system).withAmount(amount).withImpactMethod(method)
return SystemCalculator(db).calculate(setup)
def impacts_of(
process,
): # type: (dict[str, str or float]) -> Generator[dict[str, float or str]]
system = product_system_from_process(process["uuid"])
result = result_of_system(system, process["amount"])
for impact in result.getTotalImpacts():
yield {
"name": impact.impact().name,
"value": impact.value(),
"unit": impact.impact().referenceUnit,
}
def run_calculations(sheet):
for process in get_process_info(sheet):
print("Running impact calculation for %s..." % process["name"])
for impact in impacts_of(process):
print(
"The total impact on %s is %.4f %s."
% (impact["name"], impact["value"], impact["unit"])
)
run_calculations(sheet)
Store the results in a new sheet
Now that we have the results, we can store them in sheets. Let's modify the callback function so that it creates a new sheet for each process and stores the results in it.
def get_or_create_sheet(workbook, name): # type: (XSSFWorkbook, str) -> XSSFSheet
sheet = workbook.getSheet(name)
if sheet is None:
return workbook.createSheet(name)
else:
return sheet
def write_impacts_to_sheet(
sheet, impacts
): # type: (XSSFSheet, dict[str, float or str]) -> None
row = sheet.createRow(0)
row.createCell(0).setCellValue("Name")
row.createCell(1).setCellValue("Value")
row.createCell(2).setCellValue("Unit")
for i, impact in enumerate(impacts):
row = sheet.createRow(i + 1)
row.createCell(0).setCellValue(impact["name"])
row.createCell(1).setCellValue(impact["value"])
row.createCell(2).setCellValue(impact["unit"])
for i in range(3):
sheet.autoSizeColumn(i)
for process in get_process_info(sheet):
sheet = get_or_create_sheet(workbook, process["name"])
print("Running impact calculation for %s..." % process["name"])
impacts = list(impacts_of(process))
write_impacts_to_sheet(sheet, impacts)
# Write the workbook content to the file
output_stream = FileOutputStream(PATH)
workbook.write(output_stream)
# Close the input and output streams to ensure data is properly saved
input_stream.close()
output_stream.close()
# Close the workbook to free resources
workbook.close()
print("Done")